Deploy a Dockerized Application to Azure Kubernetes Service using Azure YAML Pipelines 4 – Running a Dockerized Application Locally
This is the fourth post in a series where I'm taking a fresh look at how to deploy a dockerized application to Azure Kubernetes Service (AKS) using Azure Pipelines after having previously blogged about this in 2018. The list of posts in this series is as follows:
- Getting Started
- Terraform Development Experience
- Terraform Deployment Pipeline
- Running a Dockerized Application Locally (this post)
- Application Deployment Pipelines
- Telemetry and Diagnostics
In this post I explain the components of the sample application I wrote to accompany this (and the previous) blog series and how to run the application locally. If you want to follow along you can clone / fork my repo here, and if you haven't already done so please take a look at the first post to understand the background, what this series hopes to cover and the tools mentioned in this post. Additionally, this post assumes you have created the infrastructure—or at least the Azure SQL dev database—described in the previous Terraform posts.
MegaStore Application
The sample application is called MegaStore and is about as simple as it gets in terms of a functional application. It's a .NET Core 3.1 application and the idea is that a sales record (beers from breweries local to me if you are interested) is created in the presentation tier which eventually gets persisted to a database via a message queue. The core components are:
- MegaStore.Web: a skeleton ASP.NET Core application that creates a ‘sales' record every time the home page is accessed and places it on a message queue.
- NATS message queue: this is an instance of the nats image on Docker Hub using the default configuration.
- MegaStore.SaveSaleHandler: a .NET Core console application that monitors the NATS message queue for new records and saves them to an Azure SQL database using EF Core.
When running locally in Visual Studio 2019 these application components work together using Docker Compose, which is a separate project in the Visual Studio solution. There are two configuration files in use which get merged together:
- docker-compose.yml: contains the configuration for megastore.web and megastore.savesalehandler which is common to running the application both locally and in the deployment pipeline.
- docker-compose.override.yml: contains additional configuration that is only needed locally.
There's a few steps you'll need to complete to run MegaStore locally.
Azure SQL dev Database
First configure the Azure SQL dev database created in the previous post. Using SQL Server Management Studio (SSMS) login to Azure SQL where Server name will be something like yourservername-asql.database.windows.net and Login and Password are the values supplied to the asql_administrator_login_name and asql_administrator_login_password Terraform variables. Once logged in create the following objects using the files in the repo's sql folder (use Ctrl+Shift+M in SSMS to show the Template Parameters dialog to add the dev suffix):
- A SQL login called sales_user_dev based on create-login-template.sql. Make a note of the password.
- In the dev database a user called sales_user and a table called Sale based on configure-database-template.sql.
Note: if you are having problems logging in to Azure SQL from SSMS make sure you have correctly set a firewall rule to allow your local workstation to connect.
Docker Environment File
Next create a Docker environment file to store the database connection string. In Visual Studio create a file called db-credentials.env in the docker-compose project. All on one line add the following connection string, substituting in your own values for the server name and sales_user_dev password:
|
|
DB_CONNECTION_STRING=Server=tcp:yourservername.database.windows.net,1433;Initial Catalog=dev;Persist Security Info=False;User ID=sales_user_dev;Password=yourpassword;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30; |
Note: since this file contains sensitive data it's important that you don't add it to version control. The .gitignore file that's part of the repo is configured to ignore db-credentials.env.
Application Insights Key
In order to collect Application Insights telemetry from a locally running MegaStore you'll need to edit docker-compose.override.yml to contain the instrumentation key for the dev instance of the Application Insights resource that was created in the the previous post. You can find this in the Azure Portal in the Overview pane of the Application Insights resource:

I'll write more about Application Insights in a later post but in the meantime if you want to know more see this post from my previous 2018 series. It's largely the same with a few code changes for newer ways of doing things with updated NuGet packages.
Set docker-compose as Startup
The startup project in Visual Studio needs to be set to docker-compose by right-clicking docker-compose in the Solution Explorer and selecting Set as Startup Project:
Up and Running
You should now be able to run MegaStore using F5 which should result in a localhost+port number web page in your browser. Docker Desktop will need to be running however I've noticed that newer versions of Visual Studio offer to start it automatically if required. Notice in Visual Studio the handy Containers window that gives some insight into what's happening:

In order to establish everything is working open SSMS and run select-from-sales.sql (in the sql folder in the repo) against the dev database. You should see a new ‘beer' sales record. If you want to create more records you can keep reloading the web page in your browser or run the generate-web-traffic.ps1 PowerShell snippet that's in the repo's pipeline folder making sure that the URL is something like http://localhost:32768/ (your port number will likely be different).
To view Application Insights telemetry (from the Azure Portal) whilst running MegaStore locally you may need to be aware of services running on you network that could cause interference. For me I could run Live Metrics and see activity in most of the graphs, however I initially couldn't use the Search feature to see trace and request telemetry (the screenshot is what I was expecting to see):

I initially thought this might be a firewall issue but it wasn't, and instead it turned out to be the pi-hole ad blocking service I have running on my network. It's easy to disable pi-hole for a few minutes or you can figure out which URL's need whitelisting. The bigger picture though is that if you don't see telemetry—particularly in a corporate scenario—you may have to do some investigation.
That's it for now! Next time we look at deploying MegaStore to AKS using Azure Pipelines.
Cheers -- Graham
Upgrade a Dockerized ASP.NET Core Application to the Latest Version of .NET Core
In the combined worlds of .NET Core and Docker things are changing pretty quickly and at some point you may well find yourself wanting to upgrade your Dockerized ASP.NET Core application. If you are upgrading a production application then you'll certainly want to follow the official guidance. In my case and for the purposes of this blog post I'm more concerned with the upgrade from a Docker perspective. It's not difficult however there are a few steps which can leave you scratching your head if you miss them out so I'm documenting my process for upgrading as it will certainly help me in the future and hopefully someone else as well.
Upgrading ASP.NET Core
- Download and install the latest version of .NET Core from here. From a command prompt run dotnet --list-runtimes to show what you have installed. In my case the latest version was 2.1.2.
- Ensure you are running the latest version of Visual Studio 2017. At the time of writing version 15.8.0 had just been released.
- Open your VS solution and from the Application tab of the Properties page of each project you want to upgrade change the Target framework to the required version:

- Using your technique of choice now upgrade all of the NuGet packages for the solution.
Upgrading Docker files
This is the bit which will have you scratching your head if your Docker files are targeting an earlier version of .NET Core than the version you have just upgraded to as your solution will build but not run under Docker. The error message (something like "It was not possible to find any compatible framework version. The specified framework ‘Microsoft.NETCore.App', version ‘2.1.0' was not found.") makes complete sense when you remember it is being generated from a container running an earlier version of .NET Core.
The answer of course is to change the Docker files in your solution to refer to an image running a later version of .NET Core. However, this is also a great opportunity to upgrade your Docker files to the latest specification used in new Visual Studio projects, as it does seem to change on every release. I do this by simply creating a new ASP.NET Code project in Visual Studio and then working out what needs to change in the Docker file I'm upgrading. In my case this saw my Docker file change from
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
FROM microsoft/aspnetcore:2.0 AS base WORKDIR /app EXPOSE 80 FROM microsoft/aspnetcore-build:2.0 AS build WORKDIR /src COPY MegaStore.sln ./ COPY MegaStore.Web/MegaStore.Web.csproj MegaStore.Web/ RUN dotnet restore -nowarn:msb3202,nu1503 COPY . . WORKDIR /src/MegaStore.Web RUN dotnet build -c Release -o /app FROM build AS publish RUN dotnet publish -c Release -o /app FROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "MegaStore.Web.dll"] |
to
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
FROM microsoft/dotnet:2.1-aspnetcore-runtime AS base WORKDIR /app EXPOSE 80 FROM microsoft/dotnet:2.1-sdk AS build WORKDIR /src COPY ["MegaStore.Web/MegaStore.Web.csproj", "MegaStore.Web/"] RUN dotnet restore "MegaStore.Web/MegaStore.Web.csproj" COPY . . WORKDIR "/src/MegaStore.Web" RUN dotnet build "MegaStore.Web.csproj" -c Release -o /app FROM build AS publish RUN dotnet publish "MegaStore.Web.csproj" -c Release -o /app FROM base AS final WORKDIR /app COPY --from=publish /app . ENTRYPOINT ["dotnet", "MegaStore.Web.dll"] |
The obvious changes to the specification are the removal of -nowarn:msb3202,nu1503 and changes to the Docker syntax. I'm not sure what improvements changes to the syntax bring however it makes sense to me to keep up with the latest thinking from the folks writing the Docker files for Visual Studio projects.
On the face of it your project should now run as it did before the upgrade. However in my case I was still getting error messages as per this GitHub issue. The problem for me was an outdated microsoft/dotnet:2.1-aspnetcore-runtime image and running docker pull microsoft/dotnet:2.1-aspnetcore-runtime got things running again. Probably just something peculiar to my machine due all the testing I do but if you run in to this then hopefully this will do the trick.
Cheers -- Graham
Build a Raspberry Pi Vehicle Interior Monitor – Overview
Over the past year or so I've been teaching myself whole new areas of learning based around the Raspberry Pi, including Linux, GPIO programming, basic electronics and Windows 10 IoT Core. I'm now at a point where I'm ready to build something that might be half useful, and I thought it might be helpful to someone if I blogged about my fledgling maker journey.
For my first project I'm going to build a Raspberry Pi Vehicle Interior Monitor—PiVIM. The idea is that on the odd occasion when we need to leave our dogs in the car for a few minutes, PiVIM will provide extra reassurance that all the ventilation and safety measures we've provided (windows partially open, tailgate open but secured with a Ventlock Tailgate Lock type device, reflective windscreen shade and so on) are actually working, through some sort of messaging to our mobile phones.
Important notice: The aim of PiVIM is only to provide extra reassurance on top of an already very cautious approach to reluctantly leaving dogs in the car for very short periods. Dogs die in hot cars!
With the sombre stuff out of the way, sure you can buy something but where's the fun in that? Making something from scratch offers an opportunity to learn a whole new set of skills, and in a new series of blog posts I'm planning to share my journey building PiVIM. In this first post I'm setting out the big picture—the features I hope to incorporate in to PiVIM and the developer tools I'll be using.
This is the full list of posts in this series:
PiVIM Features
Here's a list of potential features that I'm considering for this project:
- Temperature measurement. The key requirement for this project is to monitor the temperature of a vehicle's interior. A popular component for temperature measurement is the DS18B20. This comes as a small three-pin unit that looks like a transistor and also a waterproof version with the sensor embedded in a metal tube at the end of an attached wire. The waterproof version looks most useful for my project due to ruggedness and flexibility of being on the end of a wire.
- Mobile connectivity. Since PiVIM will need to work in remote locations it will need a mobile internet connection. There's a cost to this of course, and I want to keep costs as low as possible. One of the problems with most mobile broadband plans is that they are based on a monthly data allowance and at the end of each monthly period any unused allowance is lost. Given that PiVIM might be used a lot in summer and very little in winter such a plan would likely be wasteful and uneconomic. Happily the Three network have a PAYG SIM where the data allowance lasts for as long as it isn't used. I'm planning to partner this SIM with either the ZTE MF730 3G USB dongle or the ZTE MF823 4G USB dongle, and both, if Google searches are anything to go by, should work with the Raspberry Pi.
- Data access. Related to mobile connectivity is how to access the data that PiVIM generates. In addition to sending SMS alerts, the options that I'm considering are to store all data locally and make it accessible via a website running on the Pi, or to upload it to somewhere like Microsoft Azure and access it from there. Lots to research needed here, not least because although I have plenty of experience with Microsoft Azure right now I have no idea if it's possible to host a website on a Raspberry Pi that's accessible via a mobile broadband connection.
- Battery powered. Although PiVIM could use a vehicle's 12V power supply via a USB adaptor the cabling would be messy and a dedicated battery feels more suitable. Tests with a RAVPower 22000mAh portable charger and a Raspberry Pi Model B with camera attached showed that the RAVPower could keep the Pi going for at least 36 hours (I stopped the test before the RAVPower was fully drained) so a unit like this feels like it will be a good choice. It would also be useful to have some power management system to monitor the battery's charge status.
- Onboard display. I want to be able to see some basic information about PiVIM whilst it's running—mobile broadband signal strength, current temperature and so on. I've seen the Pimoroni Display-O-Tron HAT used for this purpose and was impressed, so that will probably be my starting point.
- Power button. Raspberry Pis don't come with a power button and if left connected they will also gradually drain a battery even when powered down so I'll want some sort of solution to these problems.
- Camera pictures. More of a nice to have rather than a necessity, but since the Raspberry Pi has a very handy camera module available as an accessory I might try and see if it's viable to access pictures over mobile broadband.
- Robust case. The PiVIM internals will need to be well protected so some sort of robust case will be essential. It will need to be able to house the battery as well as the Pi, ZTE USB dongle and the Display-O-Tron. Current thinking is an electrical junction box such as the one here might be a good starting point, with the Display-O-Tron screwed to the exterior surface of the lid and connected to the Pi with something like the Pimoroni Mini Black HAT Hack3r.
- Raspberry Pi model. I'll be prototyping on a Pi 3 Model B but might switch to a lower-powered board when it comes to building something that will be used out in the field.
Development Environment and Tools
I'll be starting off coding in Python, however a developer friend has very good things to say about developing with Kotlin for the Raspberry Pi so I'll probably try my hand at a Kotlin port once I have a Python version working.
In an ideal world I'd do all development directly on the Pi since there will be quite a lot of Python libraries that are talking directly to Pi hardware or to hardware attached to the Pi. In practice though I find that the development experience on the Pi doesn't give me what I want either in terms of performance or in the coding tools I want to use. Since I do a lot of work with Microsoft technologies my current development workstation is running Windows 10 and I use scp to push code out to the Pi which is running in headless mode on my local network. My configuration is as follows:
- Windows 10 Pro with the Windows Subsystem for Linux (WSL) installed and a registry setting to ‘Open Bash window here‘.
- I used to go to the trouble of giving my Pis fixed IP addresses so I could always be certain which one I was connecting to. I don't bother now and instead have Bonjour Print Services for Windows installed so that I can remote to a Pi using the hostname.local format. This works a treat in applications such as FileZilla and PuTTY. Unfortunately there is currently a bug in WSL which stops this from working. WSL is still in beta so hopefully this will be fixed soon.
- I do find it's worth configuring SSH to use certificate authentication to avoid having to deal with passwords, and have the same certificate set up for both Windows 10 and WSL.
- Python obviously needs to be installed—I just go for the latest version from the website here which also installs pip.
- One of the issues with Python development is that if you don't do anything about it packages are installed globally. This creates problems if you need to create or edit Python code that needs a specific version of a package, or indeed Python itself. The solution to this is to use virtual environments courtesy of Virtualenv and (on Windows) virtualenvwrapper-win. There's a great guide to configuring and using virtual environments on Windows here.
- I'm using Git for version control and the Python version of PiVIM is on my GitHub site here.
- My lightweight code editor of choice is Visual Studio Code. It's free and Python is fully supported with the help of Don Jayamanne's Python extension. The best way to start Visual Studio Code if you are using virtual environments is from the command line of a virtual environment using code . (make sure you don't miss off the period). Whilst you are at the command line make sure you install pylint (pip install pylint) in to your virtual environment and any other packages your code needs.
- My heavyweight IDE of choice is Visual Studio. A free version is available and it's got a huge amount of support for Python via the Python tools. Whilst I don't use it on a daily basis for Python development it's great for remote debugging using the ptvsd package. Anyone who's used Visual Studio to develop .NET applications will love and appreciate the debugging experience and there are details on how to set up this awesomeness here.
- I have FileZilla and PuTTY installed and have them configured to connect to my Raspberry Pi devices using SSH and certificate authentication. I have a bash script under version control on my Windows 10 workstation file system which I run from WSL (one of the handy things about WSL is that it can see the Windows 10 file system). The bash script uses scp to copy Python files to the Pi, after which I switch to PuTTY to run the code. A bit clunky but it works. (UPDATE: I've stopped using the bash script as it was too cumbersome. I now clone my code from GitHub to the Pi and and then in a PuTTY connection to the Pi—after having pushed code to GitHub—I run a command such as git pull && python3 module_to_run.py).
That's it for now! Watch out for my next post in this series where I'll be getting stuck in to the details.
Cheers—Graham
Continuous Delivery with Containers – Say Goodbye to IIS Express and LocalDB, with Visual Studio 2017, Docker and Windows Containers
A view I've heard expressed a few times recently, and which I completely agree with, is that we need to be discovering problems with our applications as far to the left as possible since it's much cheaper to fix problems there than further down the line towards—or even in—production. So with this in mind is it just me who feels slightly uneasy that in the Visual Studio world the development and debugging of applications destined for Windows servers tends be on Windows desktop machines using lightweight counterparts of server applications such as IIS Express to host ASP.NET websites and LocalDB to host SQL Server databases? With this setup it seems like we could be storing up trouble for later in the pipeline...
Whether my unease is justified or not, I need feel troubled no more since the world of containers offer us a solution! Since Docker for Windows now supports Windows Containers and Visual Studio 2017 has support for Docker built-in we can now develop server applications on Windows 10 and run and debug them on the exact same operating systems they will run on in production.
In this post I take my version of Contoso University that I've been using for several years now and amend it so that in the developer inner loop phase (ie everything that happens before code is checked in to the build server) the website runs in a Windows Server 2016 container running IIS (rather than IIS Express) and the SQL Server Database Project runs on SQL Server 2016 (rather than LocalDB).
Development Environment
The world of containers is evolving rapidly and the tooling might have changed by the time you read this. At the time of writing my environment is as follows:
- Windows 10 Professional version 1703 (OS Build 15063.250)
- Visual Studio Enterprise 2017 version 15.1 (26403.7) with the ASP.NET and web development workload
- Docker for Windows 17.03.1-ce running Windows containers (I recommend the stable channel as at the time of writing the edge version had a bug that caused a problem for Docker support in Visual Studio)
Depending on the speed of your internet connection you might want to docker pull the following images if you are planning on following along:
It's perhaps worth saying here that I'm using these images for convenience because they are available on Docker Hub. In a production scenario you probably wouldn't want to rely on an image as fully formed as microsoft/aspnet and you would probably start with microsoft/windowsservercore or microsoft/nanoserver and have full control of what is installed. You definitely wouldn't start with microsoft/mssql-server-windows-developer of course.
The Contoso University sample application is essentially the same as Microsoft's version except I've changed the database from Entity Framework Code First to a SQL Server Database Project. I've also changed the application to work with SQL Server authentication (rather than Windows authentication) thus removing the need for a domain controller to supply a domain account. You can get the starting point code from here and the final code here.
Adding Initial Docker Support
The first step towards Dockerizing Contoso University is to add initial Docker support for the ASP.NET web application (out-of-the-box support for SQL Server Database Projects isn't available). This is a simple as right-clicking the ContosoUniversity.Web project and choosing Add > Docker Support. This has three main visible effects:
- A new docker-compose ‘project' is added at Solution level and is made the Startup Project. This project contains several .yml files.
- A Dockerfile file and a (nested) .dockerignore file are added to ContosoUniversity.Web.
- The toolbar button that normally launches a browser has now switched to launching Docker:

The Dockerfile added to ContosoUniversity.Web is based on the microsoft/aspnet image so at this point you should now be able to run the application using the Docker toolbar button and have the website run in a Windows Container based on that image. The database side of things isn't working at this stage of course—Web.config is pointing to LocalDB and the container running the website can't see LocalDB.
To understand what has been created, open a PowerShell session and run docker images followed by docker ps. You should see that an image called contosouniversity.web has been created with a dev tag, and that this image has been used to create a container called something like dockercompose362878786_contosouniversity.web_1.
Adding Docker Support for the SQL Server Database Project
Adding Docker support for the SQL Server Database Project requires the following steps:
- Manually add a Dockerfile file and .dockerignore file to the root of ContosoUniversity.Database. Given that these files don't have file extensions and that database projects are quite prescriptive about what they think you should be adding it's easier to add them outside of Visual Studio and then add them in as existing items. (Note that if you are using Windows Explorer you'll need to create .dockerignore as .dockerignore.—Windows will drop the trailing period).
- Optionally, close Visual Studio and reopen the solution folder in a text editor such as Visual Studio Code. Open ContosoUniversity.Database.sqlproj and search for the Dockerfile and .dockerignore entries. Change them to look as follows to achieve the nested file effect in Visual Studio:
|
|
<None Include="Dockerfile" /> <None Include=".dockerignore"> <DependentUpon>Dockerfile</DependentUpon> </None> |
- .dockerignore just needs to contain an asterisk—meaning everything should be ignored.
- Dockerfile should contain the following code:
|
|
# escape=` FROM microsoft/mssql-server-windows-developer SHELL ["powershell", "-Command", "$ErrorActionPreference = 'Stop';"] EXPOSE 1433 VOLUME c:\database ENV sa_password Very$trOngPa$$word! ENV ACCEPT_EULA=Y |
- Switching to the docker-compose ‘project', docker-compose.yml should be amended to the following:
|
|
version: '2.1' services: contosouniversity.database: image: contosouniversity.database build: .\ContosoUniversity.Database contosouniversity.web: image: contosouniversity.web build: .\ContosoUniversity.Web depends_on: - contosouniversity.database |
- A change is also needed to docker-compose.vs.debug.yml which should be amended to the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
version: '2.1' services: contosouniversity.web: image: contosouniversity.web:dev build: args: source: ${DOCKER_BUILD_SOURCE} volumes: - .\ContosoUniversity.Web:C:\inetpub\wwwroot - ~\msvsmon:C:\msvsmon:ro labels: - "com.microsoft.visualstudio.targetoperatingsystem=windows" contosouniversity.database: image: contosouniversity.database:dev labels: - "com.microsoft.visualstudio.targetoperatingsystem=windows" |
At this point you should be able to run the application using the Docker toolbar button and again see the website running—in a Windows container. However this time a second image (contosouniversity.database, tagged with dev) and corresponding container (named something like dockercompose362878786_contosouniversity.database_1) will have been created, with the container now running SQL Server. This is a newly minted instance of SQL Server and doesn't have a database for our website to connect to, which is the next issue to address.
Connecting the Contoso University Website to its Database
These next steps assume you are following on from the previous section, ie that the website is open in a browser and that Visual Studio is still debugging.
- Leave the browser open but stop debugging in Visual Studio.
- In ContosoUniversity.Web edit Web.config so that the connection string Data Source points to contosouniversity.database:
|
|
<connectionStrings> <add name="SchoolContext" connectionString="Data Source=contosouniversity.database;Initial Catalog=ContosoUniversity;User Id=ContosoUniversity;Password=MySuperStrongPassw0rd!" providerName="System.Data.SqlClient" /> </connectionStrings> |
- In a PowerShell session, find the IP address of the container running SQL Server using docker inspect and passing in enough of the container's ID to make it unique:
|
|
docker inspect --format="{{.NetworkSettings.Networks.nat.IPAddress}}" <container ID> |
- In ContosoUniversity.Database edit ContosoUniversity.publish.xml so that the Target database connection points to the IP address of the SQL Server container and change the the authentication to SQL Server Authentication. The User Name should be sa (yes—I know) the password should be the same as the one specified in the Dockerfile used to build the database image. Save the profile and then click Publish.
- Back in the web browser running the Contoso University website, click on one of the menu bar links (eg Departments) that causes a database query. If everything has worked you should now have a fully functioning application.
Understanding the Developer Inner Loop Workflow
At this point we have achieved our aim of running and debugging both the website and database components of Contoso University in containers running operating systems that are the same as would be used in production. Once the images and containers have been created they will—as far as my testing is concerned—continue to be used as long as nothing changes. This is the case even if Visual Studio, Docker or even the workstation are restarted. The great thing is that any changes made to the containers—for example updating the database schema—will be preserved. Of course, if something changes in one of the Dockerfile files the images and containers will be rebuilt and in the case of the database the publish file will need to be updated with a new IP address and the database will need to be published again from scratch. Also, if the solution is cleaned (ie Build > Clean Solution) the containers are removed and rebuilt, again necessitating publishing the database from scratch. Overall though, the developer inner loop workflow feels quite slick.
Next Steps
As things stand the compose and Dockerfile files are not ready to be used in a continuous delivery pipeline. The website Dockerfile for example has Contoso University being deployed as the Default Web Site rather than a ContosoUniversity website and the database Dockerfile doesn't cater for any persistent storage. There is also the problem of checking in the database project's publish profile with an IP address specific to one developer's workstation—a real pain for other developers. I'll address these issues as part of getting Contoso University working in a Docker-based continuous delivery pipeline in the next post in this series.
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Server Configuration as Code with PowerShell DSC
I suspect I'm on reasonably safe ground when I venture to suggest that most software engineers developing applications for Windows servers (and the organisations they work for) have yet to make the leap from just writing the application code to writing both the application code and the code that will configure the servers the application will run on. Why do I suggest this? It's partly from experience in that I've never come across anyone developing for the Windows platform who is doing this (or at least they haven't mentioned it to me) and partly because up until fairly recently Microsoft haven't provided any tooling for implementing configuration as code (as this engineering practice is sometimes referred to). There are products from other vendors of course but they tend to have their roots in the Linux world and use languages such as Ruby (or DSLs based on Ruby) which is probably going to seriously muddy the waters for organisations trying to get everyone up to speed with PowerShell.
This has all changed relatively recently with the introduction of PowerShell DSC, Microsoft's solution for implementing configuration as code on Windows (and other platforms as it happens). With PowerShell DSC (and related technologies) the configuration of servers is expressed as programming code that can be versioned in source control. When a change is required to a server the code is updated and the new configuration is then applied to the server. This process is usually idempotent, ie the configuration can be applied repeatedly and will always give the same result. It also won't generate errors if the configuration is already in the desired state. Through version control we can audit how a configuration changes over time and being code it can be applied as required to ensure server roles in different environments, or multiple instances of the same server role in the same environment, have a consistent configuration.
So ostensibly Windows server developers now have no excuse not to start implementing configuration as code. But if we've managed so far without this engineering practice why all the fuss now? What benefit is it going to bring to the table? The key benefit is that it's a cure for that age-old problem of servers that might start life from a build script, but over the months (and possibly years) different technicians make necessary tweaks here and there until one day the server becomes a unique work of art that nobody could ever hope to reproduce. Server backups become critical and everyone dreads the day that the server will need to be upgraded or replaced.
If your application is very simple you might just get away with this state of affairs -- not that it makes it right or a best practice. However if your application is constantly evolving with concomitant configuration changes and / or you are going down the microservices route then you absolutely can't afford to hand-crank the configuration of your servers. Not only is the manual approach very error prone it's also hugely time-consuming, and has no place in a world of continuous delivery where shortening lead times and increasing reliability and repeatability is the name of the game.
So if there's no longer an excuse to implement configuration as code on the Windows platform why isn't there a mad rush to adopt it? In my view, for most mid-size IT departments working with existing budgets and staffing levels and an existing landscape of hand-cranked servers it's going to be a real slog to switch the configuration of a live estate to being managed by code. Once you start thinking about the complexities of analysing exiting servers (some of which might have been around for years and which might have all sorts of bespoke applications running on them) combined with devising a system of managing scores or even hundreds of servers it's clear that a task of this nature is almost certainly going to require a dedicated team. And despite the potential benefits that configuration as code promises most mid-size IT departments are likely to struggle to stand-up such a team.
So if it's going to be hard how does an organisation get started with configuration as code and PowerShell DSC? Although I don't have anywhere near all of the answers it is already clear to me that if your organisation is in the business of writing applications for Windows servers then you need to approach the problem from both ends of the server spectrum. At the far end of the spectrum is the live estate where server ‘drift' needs to be controlled using PowerShell DSC's ‘pull' mode. This is where servers periodically reach out to a central repository to pull their ‘true' configuration and make any adjustments accordingly. At the near end of the spectrum are the servers that form the continuous delivery pipeline which need to have configuration changes applied to them just before a new version of the application gets deployed to them. Happily PowerShell has a ‘push' mode which will work nicely for this purpose. There is also the live deployment situation. Here, live servers will need to have configuration changes pushed to them before application deployment takes place and then will need to switch over to pull mode to keep them true.
The way I see things at the moment is that PowerShell DSC pull mode is going to be hard to implement at scale because of the lack of tooling to manage it. Whilst you could probably manage a handful of servers in pull mode using PowerShell DSC script files, any more than a handful is going to cause serious pain without some kind of management framework such as the one that is available for Chef. The good news though is that getting started with PowerShell DSC push mode for configuring servers that comprise the deployment pipeline as part of application development activities is a much more realistic prospect.
Big Picture Time
I'm not going to be able to cover everything about making PowerShell DSC push mode work in one blog post so it's probably worth a few words about the bigger picture. One key concept to establish early on is that the code that will configure the server(s) that an application will reside on has to live and change alongside the application code. At the very least the server configuration code needs to be in the same version control branch as the application code and frequently it will make sense for it to be part of the same Visual Studio solution. I won't be presenting that approach in this blog post and instead will concentrate on the mechanics of getting PowerShell DSC push mode working and writing the configuration code that enables the Contoso University sample application (which requires IIS and SQL Server) to run. In a future post I'll have the code in the same Visual Studio solution as the Contoso University sample application and will explain how to build an artefact that is then deployed by the release management tooling in TFS / VSTS prior to deploying the application.
For anyone who has come across this post by chance it is part of my ongoing series about Continuous Delivery with TFS / VSTS, and you may find it helpful to refer to some of the previous posts to understand the full context of what I'm trying to achieve. I should also mention that this post isn't intended to be a PowerShell DSC tutorial and if you are new to the technology I have a Getting Started post here with a link collection of useful learning resources. With all that out of the way let's get going!
Getting Started
Taking the Infrastructure solution from this blog post as a starting point (available as a code release at my Infrastructure repo on GitHub, final version of this post's code here) add a new PowerShell Script Project called ConfigurationScripts. To this new project add a new PowerShell Script file called ContosoUniversity.ps1 and add a hash table and empty Configuration block called WebAndDatabase as follows:
|
|
$configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') } ) } Configuration WebAndDatabase { } |
We're going to need an environment to deploy in to so using the techniques described in previous posts (here and here) create a PRM-DAT-AIO server that is joined to the domain. This server will need to have Windows Management Framework 5.0 installed -- a manual process as far as this particular post is concerned but something that is likely to need automating in the future.
To test a basic working configuration we'll create a folder on PRM-DAT-AIO to act as the IIS physical path to the ContosoUniversity web files. Add the following lines of code to the beginning of the configuration block:
|
|
Import-DscResource –ModuleName PSDesiredStateConfiguration Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { File WebSiteFolder { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } } |
To complete the skeleton code add the following lines of code to the end of ContosoUniversity.ps1:
|
|
WebAndDatabase -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose Start-DSCConfiguration -Path C:\Dsc\Mof -Wait -Verbose -Force |
The code contained in ContosoUniversity.ps1 should now be as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
$configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') } ) } Configuration WebAndDatabase { Import-DscResource –ModuleName PSDesiredStateConfiguration Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { File WebSiteFolder { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } } } WebAndDatabase -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose Start-DSCConfiguration -Path C:\Dsc\Mof -Wait -Verbose -Force |
Although you can create this code from any developer workstation you need to ensure that you can run it from a workstation that is joined to the same domain as PRM-DAT-AIO and has a folder called C:\Dsc\Mof. In order to keep authentication simple I'm also assuming that you are logged on to your developer workstation with domain credentials that allow you to perform DSC operations on PRM-DAT-AIO. Running this code will create a PRM-DAT-AIO.mof file in C:\Dsc\Mof which will deploy to PRM-DAT-AIO and create the folder. Magic!
Installing Resource Modules Locally
To do anything much more sophisticated than create a folder we'll need to import resources to our local workstation from the PowerShell Gallery. We'll be working with xWebAdministration and xSQLServer and they can be installed locally as follows:
|
|
Install-Module xWebAdministration -Force -Verbose Install-Module xSQLServer -Force -Verbose |
These same commands will also install the latest version of the resources if a previous version exists. Referencing these resources in our configuration script seems to have changed with the release of DSC 5.0 and versioning information is a requirement. Consequently, these resources are referenced in the configuration as follows:
|
|
Import-DscResource -ModuleName @{ModuleName="xWebAdministration";ModuleVersion="1.10.0.0"} Import-DscResource -ModuleName @{ModuleName="xSQLServer";ModuleVersion="1.5.0.0"} |
Obviously change the above code to reference the version of the module that you actually install. The resources are continually being updated with new versions and this requires a strategy to upgrade on a periodic basis.
Making Resource Modules Available Remotely
Whilst the additions in the previous section allows us to create advanced configurations on our developer workstation these configurations are not going to run against target nodes since as things stand the target nodes don't know anything about custom resources (as opposed to resources such as PSDesiredStateConfiguration which ship with the Windows Management Framework). We can fix this by telling the Local Configuration Manager (LCM) of target nodes where to get the custom resources from. The procedure (which I've adapted from Nana Lakshmanan's blog post) is as follows:
- Choose a server in the domain to host a fileshare. I'm using my domain controller (PRM-CORE-DC) as it's always guaranteed to be available under normal conditions. Create a folder called C:\Dsc\DscResources (Dsc purposefully repeated) and share it as Read/Write for Everyone as \\PRM-CORE-DC\DscResources.
- Custom resources need to be zipped in a format required by DSC the pull protocol. The PowerShell to do this for version 1.10 of xWebAdministration and 1.5 of xSQLServer (using a local C:\Dsc\Resources folder) is as follows:
|
|
Find-Module xWebAdministration | Save-Module -Path C:\Dsc\Resources -Verbose -Force Compress-Archive -Path C:\Dsc\Resources\xWebAdministration\1.10.0.0\* -DestinationPath \\prm-core-dc\DscResources\xWebAdministration_1.10.0.0.zip -Verbose -Force New-DscChecksum -Path \\prm-core-dc\DscResources\xWebAdministration_1.10.0.0.zip -OutPath \\prm-core-dc\DscResources -Verbose -Force Find-Module xSQLServer | Save-Module -Path C:\Dsc\Resources -Verbose -Force Compress-Archive -Path C:\Dsc\Resources\xSQLServer\1.5.0.0\* -DestinationPath \\prm-core-dc\DscResources\xSQLServer_1.5.0.0.zip -Verbose -Force New-DscChecksum -Path \\prm-core-dc\DscResources\xSQLServer_1.5.0.0.zip -OutPath \\prm-core-dc\DscResources -Verbose -Force |
Of course depending on the frequency of your having to do this to cope with updates and the number of resources you end up working with you probably want to re-write all this up in to some sort of reusable package.
- With the packages now in the right format in the fileshare we need to tell the LCM of target nodes where to look. We do this by creating a new configuration decorated with the [DscLocalConfigurationManager()] attribute:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[DscLocalConfigurationManager()] Configuration LocalConfigurationManager { Node $AllNodes.NodeName { Settings { RefreshMode = 'Push' AllowModuleOverwrite = $True # A configuration Id needs to be specified, known bug ConfigurationID = '3a15d863-bd25-432c-9e45-9199afecde91' ConfigurationMode = 'ApplyAndAutoCorrect' RebootNodeIfNeeded = $True } ResourceRepositoryShare FileShare { SourcePath = '\\prm-core-dc\DscResources\' } } } LocalConfigurationManager -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose |
The Settings block is used to set various properties of the LCM which are required in order for configurations we'll be writing to run. The ResourceRepositoryShare block obviously specifies the location of the zipped resource packages.
- The final requirement is to add the line of code (Set-DscLocalConfigurationManager -Path C:\Dsc\Mof -Verbose) to apply the LCM settings.
The revised version of ContosoUniversity.ps1 should now be as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
$configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') } ) } Configuration WebAndDatabase { Import-DscResource –ModuleName PSDesiredStateConfiguration Import-DscResource -ModuleName @{ModuleName="xWebAdministration";ModuleVersion="1.10.0.0"} Import-DscResource -Module @{ModuleName="xSQLServer";ModuleVersion="1.5.0.0"} Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { File WebSiteFolder { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } } } WebAndDatabase -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose [DscLocalConfigurationManager()] Configuration LocalConfigurationManager { Node $AllNodes.NodeName { Settings { RefreshMode = 'Push' AllowModuleOverwrite = $True # A configuration Id needs to be specified, known bug ConfigurationID = '3a15d863-bd25-432c-9e45-9199afecde91' ConfigurationMode = 'ApplyAndAutoCorrect' RebootNodeIfNeeded = $True } ResourceRepositoryShare FileShare { SourcePath = '\\prm-core-dc\DscResources\' } } } LocalConfigurationManager -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose Set-DscLocalConfigurationManager -Path C:\Dsc\Mof -Verbose Start-DSCConfiguration -Path C:\Dsc\Mof -Wait -Verbose -Force |
At this stage we now have our complete working framework in place and we can begin writing the configuration blocks that colectively will leave us with a server that is capable of running our Contoso University application.
Writing Configurations for the Web Role
Configuring for the web role requires consideration of the following factors:
- The server features that are required to run your application. For Contoso University that's IIS, .NET Framework 4.5 Core and ASP.NET 4.5.
- The mandatory IIS configurations for your application. For Contoso University that's a web site with a custom physical path.
- The optional IIS configurations for your application. I like things done in a certain way so I want to see an application pool called ContosoUniversity and the Contoso University web site configured to use it.
- Any tidying-up that you want to do to free resources and start thinking like you are configuring NanoServer. For me this means removing the default web site and default application pools.
Although you'll know if your configurations have generated errors how will you know if they've generated the desired result? The following ‘debugging' options can help:
- I know that the home page of Contoso University will load without a connection to a database, so I copied a build of the website to C:\inetpub\ContosoUniversity on PRM-DAT-AIO so I could test the site with a browser. You can download a zip of the build from here although be aware that AV software might mistakenly regard it as malware.
- The IIS management tools can be installed on target nodes whilst you are in configuration mode so you can see graphically what's happening. The following configuration does the trick:
|
|
WindowsFeature IISTools { Ensure = "Present" Name = "Web-Mgmt-Tools" } |
- If you are testing with a local version of Internet Explorer make sure you turn off Compatibility View or your site may render with odd results. From the IE toolbar choose Tools > Compatibility View Settings and uncheck Display intranet sites in Compatibility View.
Whilst you are in configuration mode the following resources will be of assistance:
- The xWebAdministration documentation on GitHub: https://github.com/PowerShell/xWebAdministration.
- The example files that ship with xWebAdministration: C:\Program Files\WindowsPowerShell\Modules\xWebAdministration\n.n.n.n\Examples.
- A Google search for xWebAdministration.
The configuration settings required to meet my requirements stated above are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { # Configure for web server role WindowsFeature DotNet45Core { Ensure = 'Present' Name = 'NET-Framework-45-Core' } WindowsFeature IIS { Ensure = 'Present' Name = 'Web-Server' } WindowsFeature AspNet45 { Ensure = "Present" Name = "Web-Asp-Net45" } # Configure ContosoUniversity File ContosoUniversity { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } xWebAppPool ContosoUniversity { Ensure = "Present" Name = "ContosoUniversity" State = "Started" DependsOn = "[WindowsFeature]IIS" } xWebsite ContosoUniversity { Ensure = "Present" Name = "ContosoUniversity" State = "Started" PhysicalPath = "C:\inetpub\ContosoUniversity" BindingInfo = MSFT_xWebBindingInformation { Protocol = 'http' Port = '80' HostName = 'prm-dat-aio' IPAddress = '*' } ApplicationPool = "ContosoUniversity" DependsOn = "[xWebAppPool]ContosoUniversity" } # Configure for development mode only WindowsFeature IISTools { Ensure = "Present" Name = "Web-Mgmt-Tools" } # Clean up the uneeded website and application pools xWebsite Default { Ensure = "Absent" Name = "Default Web Site" } xWebAppPool NETv45 { Ensure = "Absent" Name = ".NET v4.5" } xWebAppPool NETv45Classic { Ensure = "Absent" Name = ".NET v4.5 Classic" } xWebAppPool Default { Ensure = "Absent" Name = "DefaultAppPool" } File wwwroot { Ensure = "Absent" Type = "Directory" DestinationPath = "C:\inetpub\wwwroot" Force = $True } } |
There is one more piece of the jigsaw to finish the configuration and that's amending the application pool to use a domain account that has permissions to talk to SQL Server. That's a more advanced topic so I'm dealing with it later.
Writing Configurations for the Database Role
Configuring for the SQL Server database role is slightly different from the web role since we need to install SQL Server which is a separate application. The installation files need to be made available as follows:
- Choose a server in the domain to host a fileshare. As above I'm using my domain controller. Create a folder called C:\Dsc\DscInstallationMedia and and share it as Read/Write for Everyone as \\PRM-CORE-DC\DscInstallationMedia.
- Download a suitable SQL Server ISO image to the server hosting the fileshare -- I used en_sql_server_2014_enterprise_edition_with_service_pack_1_x64_dvd_6669618.iso from MSDN Subscriber Downloads.
- Mount the ISO and copy the contents of its drive to a folder called SqlServer2014 created under C:\Dsc\DscInstallationMedia.
In contrast to configuring for the web role there are fewer configurations required for the database role. There is a requirement to supply a credential though and for this I'm using the Key Vault technique described in this post. This gives rise to new code within and preceding the configuration hash table as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise $vaultname = 'prmkeyvault' $domainAdminPassword = Get-AzureKeyVaultSecret –VaultName $vaultname –Name DomainAdminPassword $SecurePassword = ConvertTo-SecureString -String $domainAdminPassword.SecretValueText -AsPlainText -Force $domainAdministratorCredential = New-Object System.Management.Automation.PSCredential ("PRM\graham", $SecurePassword) $configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') AppPoolUserName = 'PRM\CU-DAT' PSDscAllowDomainUser = $true PSDscAllowPlainTextPassword = $true DomainAdministratorCredential = $domainAdministratorCredential } ) } |
For a server such as the one we are configuring where the database is on the same machine as the web server and only the database engine is required there are just two configuration blocks needed to install SQL Server. For more complicated scenarios the following resources will be of assistance:
- The xSQLServer documentation on GitHub: https://github.com/PowerShell/xSQLServer.
- The example files that ship with xSQLServer: C:\Program Files\WindowsPowerShell\Modules\xSQLServer\n.n.n.n\Examples.
- A Google search for xSQLServer.
The configuration settings required for the single server scenario are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Node $AllNodes.Where({$_.Roles -contains 'Database'}).NodeName { WindowsFeature "NETFrameworkCore" { Ensure = "Present" Name = "NET-Framework-Core" } xSqlServerSetup "SQLServerEngine" { DependsOn = "[WindowsFeature]NETFrameworkCore" SourcePath = "\\prm-core-dc\DscInstallationMedia" SourceFolder = "SqlServer2014" SetupCredential = $Node.DomainAdministratorCredential InstanceName = "MSSQLSERVER" Features = "SQLENGINE" } # Configure for development mode only xSqlServerSetup "SQLServerManagementTools" { DependsOn = "[WindowsFeature]NETFrameworkCore" SourcePath = "\\prm-core-dc\DscInstallationMedia" SourceFolder = "SqlServer2014" SetupCredential = $Node.DomainAdministratorCredential InstanceName = "NULL" Features = "SSMS,ADV_SSMS" } } |
In order to assist with ‘debugging' activities I've included the installation of the SQL Server management tools but this can be omitted when the configuration has been tested and deemed fit for purpose. Later in this post we'll manually install the remaining parts of the Contoso University application to prove that the installation worked but for the time being you can run SQL Server Management Studio to see the database engine running in all its glory!
Amending the Application Pool Identity
The Contoso University website is granted access to the database via a domain account that firstly gets configured as the Identity for the website's application pool and then gets configured as a SQL Server login associated with a user which has the appropriate permissions to the database. The SQL Server configuration is taken care of by a permissions script that we'll come to shortly, and the immediate task is concerned with amending the Identity property of the ConsosoUniversity application pool so that it references a domain account.
Initially this looked like it was going to be painful since xWebAdministration doesn't currently have the ability to configure the inner workings of application pools. Whilst investigating the possibilities I had the good fortune to come across a fork of xWebAdministration on the PowerShell.org GitHub site where those guys have created a module which does what we want. I need to introduce a slight element of caution here since the fork doesn't look like it's under active development. On the other hand maybe there are no major issues that need fixing. And if there are and they aren't going to get fixed at least the code is there to be forked. Because this fork isn't in the PowerShell Gallery getting it to work locally is a manual process:
- Download the code to C:\Dsc\Resources and unblock and extract it. Change the folder name from cWebAdministration-master to cWebAdministration and copy to C:\Program Files\WindowsPowerShell\Modules.
- In the configuration block reference the module as Import-DscResource –ModuleName @{ModuleName="cWebAdministration";ModuleVersion="2.0.1″}.
The configuration required to make the resource available to target nodes has an extra manual step:
- In the root of C:\DSC\Resources\cWebAdministration create a folder named 2.0.1 and copy the contents of C:\DSC\Resources\cWebAdministration to this folder.
- The following code can now be used to package the resource and copy it to the fileshare:
|
|
Compress-Archive -Path C:\Dsc\Resources\cWebAdministration\2.0.1\* -DestinationPath \\prm-core-dc\DscResources\cWebAdministration_2.0.1.zip -Verbose -Force New-DscChecksum -Path \\prm-core-dc\DscResources\cWebAdministration_2.0.1.zip -OutPath \\prm-core-dc\DscResources -Verbose -Force |
I tend towards using a different domain account for the Identity properties of the website application pools in the different environments that make up the deployment pipeline. In doing so it protects the pipeline form a complete failure if something happens to that domain account -- it gets locked-out for example. To support this scenario the configuration block to configure the application pool identity needs to support dynamic configuration and takes the following form:
|
|
cAppPool ContosoUniversity { Name = "ContosoUniversity" IdentityType = "SpecificUser" UserName = $Node.AppPoolUserName Password = $Node.AppPoolCredential DependsOn = "[xWebAppPool]ContosoUniversity" } |
The dynamic configuration is supported by Key Vault code to retrieve the password of the domain account used to configure the application pool (not shown) and the following additions to the configuration hash table:
|
|
AppPoolUserName = 'PRM\CU-DAT' AppPoolCredential = $appPoolDomainAccountCredential |
The code does of course rely on the existence of the PRM\CU-DAT domain account (set so the password doesn't expire). This is the last piece of configuration, and you can view the final result on GitHub here.
The Moment of Truth
After all that configuration, is it enough to make the Contoso University application work? To find out:
- If you haven't already, download, unblock and unzip the ContosoUniversityConfigAsCode package from here, although as mentioned previously be aware that AV software might mistakenly regard it as malware.
- The contents of the Website folder should be copied (if not already) to C:\inetpub\ContosoUniversity on the target node.
- Edit the SchoolContext connection string in Web.config if required -- the download has the server set to localhost and the database to ContosoUniversity.
- On the target node run SQL Server Management Studio and install the database as follows:
- In Object Explorer right-click the Databases node and choose Deploy Data-tier Application.
- Navigate through the wizard, and at Select Package choose ContosoUniversity.Database.dacpac from the database folder of the ContosoUniversityConfigAsCode download.
- Move to the next page of the wizard (Update Configuration) and change the Name to ContosoUniversity.
- Navigate past the Summary page and the DACPAC will be deployed:

- Still in SSMS, apply the permissions script as follows:
- Open Create login and database user.sql from the Database\Scripts folder in the ContosoUniversityConfigAsCode download.
- If the pre-configured login/user (PRM\CU-DAT) is different from the one you are using update accordingly, then execute the script.
You can now navigate to http://prm-dat-aio (or whatever your server is called) and if all is well make a mental note to pour a well-deserved beverage of your choosing.
Looking Forward
Although getting this far is certainly an important milestone it's by no means the end of the journey for the configuration as code story. Our configuration code now needs to be integrated in to the Contoso University Visual Studio solution so that it can be built as an artefact alongside the website and database artefacts. We then need to be able to deploy the configuration before deploying the application -- all automated through the new release management tooling that has just shipped with TFS 2015 Update 2 or through VSTS if you are using that. Until next time...
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Join a VM to a Domain with Azure Resource Manager Templates
In the previous post in my blog post series on Continuous Delivery with TFS / VSTS we learned how to provision a Windows Server virtual machine using Azure Resource Manager templates. The next major step in this quest to automate the creation and configuration of the infrastructure to which we'll deploy our application is to configure server internals, starting with joining a VM to the domain. My initial thinking was that this would need to be some kind of PowerShell command, and whilst this is an option I was very pleased to find that there is an ARM template resource to do this. The resource in question goes by the name of JsonADDomainExtension; it's a VM extension and you can read about it (and the PowerShell commands to do the same thing) in this blog post.
I have to confess that I struggled to get the extension to work at first. I spent a whole afternoon fiddling with the settings and getting nowhere, and spent quite a bit of time reading forum posts from others who were having similar difficulties (mostly with the PowerShell commands though). I gave up in frustration, only to come back to it a few days later to try again to find it was all working! I describe the steps I took below -- please be aware that it's very much a direct continuation of this post so please do check that out first if you haven't done so already.
Adding the JsonADDomainExtension to the JSON Template
Getting starting with the extension is very easy, as it's just a case of dropping the JSON in to the resources part of the template. The code I initially used to make the extension work was as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "apiVersion": "2015-06-15", "type": "Microsoft.Compute/virtualMachines/extensions", "name": "[concat(variables('nodeNameToLower'),'/joindomain')]", "location": "[resourceGroup().location]", "dependsOn": [ "[concat('Microsoft.Compute/virtualMachines/', variables('nodeNameToUpper'))]" ], "tags": { "displayName": "JoinDomain" }, "properties": { "publisher": "Microsoft.Compute", "type": "JsonADDomainExtension", "typeHandlerVersion": "1.0", "settings": { "Name": "prm.local", "OUPath": "", "User": "prm\\graham", "Restart": "true", "Options": "3" }, "protectedsettings": { "Password": "MySuperSecureDomainAdminPassword" } } } |
I added this code to the WindowsServer2012R2Datacenter.json file which has variables defined for use where the VM name is required. Note that OUPath can be an empty string, the requirement for the escaped backslash for the (domain) User and the use of the magic number 3 in Options (just go with it or see here for the details).
Whilst this (eventually) worked fine for me the big issue was how to hide the password for the account that will join the VM to the domain. I hard coded it in to the template to get the extension working but even when refactored as a parameter the password is still in plain view -- now just in the PowerShell calling script.
Say Hello to Azure Key Vault
As luck would have it around the time I was initially getting JsonADDomainExtension to work I watched Cloud Cover Episode 200: Azure Resource Manager Tooling with Brian Moore where Brian mentioned the forthcoming ability to use Azure Key Vault to supply secret values such as passwords to ARM templates. Following a very helpful email exchange Brian pointed me towards this page which is a partial answer to the solution I wanted to get working.
At the time of writing there was no portal interface for configuring Azure Key Vault so it's over to PowerShell (no bad thing) to create a new vault:
|
|
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise New-AzureRmKeyVault -VaultName 'prmkeyvault' -ResourceGroupName PRM-COMMON -Location 'West Europe' |
In the code above this creates a vault named prmkeyvault. Next we need to add our password as a secret:
|
|
$secretValue = ConvertTo-SecureString 'MySuperSecureDomainAdminPassword' -AsPlainText -Force Set-AzureKeyVaultSecret -VaultName 'prmkeyvault' -Name 'DomainAdminPassword' -SecretValue $secretValue |
This creates a new secret called DomainAdminPassword. Of course, the objects that have just been created can be examined with Azure Resource Explorer:

Use the Secret in the JSON Template
The Microsoft guidance for passing secrets to templates is based on the use of an ARM parameters file. This wasn't quite what I wanted as I'm using a PowerShell script to supply my parameters. The way to access secrets using PowerShell is along the following lines:
|
|
# Assumes authentication has already been made $domainAdminPassword = Get-AzureKeyVaultSecret –VaultName prmkeyvaulttest –Name DomainAdminAdminPassword # Use this syntax to return the secret $domainAdminPassword.SecretValueText |
You can see how I integrated the code above in to my PowerShell script by examining Create PRM-DAT.ps1 in the code release that accompanies this post on my Infrastructure repository on GitHub. It's not quite the full solution at the moment though because despite having a mechanism in place for automatically authenticating to Azure PowerShell the use of Azure Key Vault cmdlets in the script causes the authentication dialog to pop-up. I'm still working on how to stop that -- if you know please leave a message in the comments!
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Infrastructure as Code with Azure Resource Manager Templates
So far in this blog post series on Continuous Delivery with TFS / VSTS we have gradually worked our way to the position of having a build of our application which is almost ready to be deployed to target servers (or nodes if you prefer) in order to conduct further testing before finally making its way to production. This brings us to the question of how these nodes should be provisioned and configured. In my previous series on continuous delivery deployment was to nodes that had been created and configured manually. However with the wealth of automation tools available to us we can -- and should -- improve on that. This post explains how to achieve the first of those -- provisioning a Windows Server virtual machine using Azure Resource Manager templates. A future post will deal with the configuration side of things using PowerShell DSC.
Before going further I should point out that this post is a bit different from my other posts in the sense that it is very specific to Azure. If you are attempting to implement continuous delivery in an on premises situation chances are that the specifics of what I cover here are not directly usable. Consequently, I'm writing this post in the spirit of getting you to think about this topic with a view to investigating what's possible for your situation. Additionally, if you are not in the continuous delivery space and have stumbled across this post through serendipity I do hope you will be able to follow along with my workflow for creating templates. Once you get past the Big Picture section it's reasonably generic and you can find the code that accompanies this post at my GitHub repository here.
The Infrastructure Big Picture
In order to understand where I am going with this post it's probably helpful to understand the big picture as it relates to this blog series on continuous delivery. Our final continuous delivery pipeline is going to consist of three environments:
- DAT -- development automated test where automated UI testing takes place. This will be an ‘all in one' VM hosting both SQL Server and IIS. Why have an all-in-one VM? It's because the purpose of this environment is to run automated tests, and if those tests fail we want a high degree of certainty that it was because of code and not any other factors such as network problems or a database timeout. To achieve that state of certainty we need to eliminate as many influencing variables as possible, and the simplest way of achieving that is to have everything running on the same VM. It breaks the rule about early environments reflecting production but if you are in an on premises situation and your VMs are on hand-me-down infrastructure and your network is busy at night (when your tests are likely running) backing up VMs and goodness knows what else then you might come to appreciate the need for an all-in-one VM for automated testing.
- DQA -- development quality assurance where high-value manual testing takes place. This really does need to reflect production so it will consist of a database VM and a web server VM.
- PRD -- production for the live code. It will consist of a database VM and a web server VM.
These environments map out to the following infrastructure I'll be creating in Azure:
- PRM-DAT -- resource group to hold everything for the DAT environment
- PRM-DAT-AIO -- all in one VM for the DAT environment
- PRM-DQA -- resource group to hold everything for the DQA environment
- PRM-DQA-SQL -- database VM for the DQA environment
- PRM-DQA-IIS -- web server VM for the DQA environment
- PRM-PRD -- resource group to hold everything for the DQA environment
- PRM-PRD-SQL -- database VM for the PRD environment
- PRM-PRD-IIS -- web server VM for the PRD environment
The advantage of using resource groups as containers is that an environment can be torn down very easily. This makes more sense when you realise that it's not just the VM that needs tearing down but also storage accounts, network security groups, network interfaces and public IP addresses.
Overview of the ARM Template Development Workflow
We're going to be creating our infrastructure using ARM templates which is a declarative approach, ie we declare what we want and some other system ‘makes it so'. This is in contrast to an imperative approach where we specify exactly what should happen and in what order. (We can use an imperative approach with ARM using PowerShell but we don't get any parallelisation benefits.) If you need to get up to speed with ARM templates I have a Getting Started blog post with a collection useful useful links here. The problem -- for me at least -- is that although Microsoft provide example templates for creating a Windows Server VM (for instance) they are heavily parametrised and designed to work as standalone VMs, and it's not immediately obvious how they can fit in to an existing network. There's also the issue that at first glance all that JSON can look quite intimidating! Fear not though, as I have figured out what I hope is a great workflow for creating ARM templates which is both instructive and productive. It brings together a number of tools and technologies and I make the assumption that you are familiar with these. If not I've blogged about most of them before. A summary of the workflow steps with prerequisites and assumptions is as follows:
- Create a Model VM in Azure Portal. The ARM templates that Microsoft provide tend to result in infrastructure that have different internal names compared with the same infrastructure created through the Azure Portal. I like how the portal names things and in order to help replicate that naming convention for VMs I find it useful to create a model VM in the portal whose components I can examine via the Azure Resource Explorer.
- Create a Visual Studio Solution. Probably the easiest way to work with ARM templates is in Visual Studio. You'll need the Azure SDK installed to see the Azure Resource Group project template -- see here for more details. We'll also be using Visual Studio to deploy the templates using PowerShell and for that you'll need the PowerShell Tools for Visual Studio extension. If you are new to this I have a Getting Started blog post here. We'll be using Git in either TFS or VSTS for version control but if you are following this series we've already covered that.
- Perform an Initial Deployment. There's nothing worse than spending hours coding only to find that what you're hoping to do doesn't work and that the problem is hard to trace. The answer of course is to deploy early and that's the purpose of this step.
- Build the Deployment Template Resource by Resource Using Hard-coded Values. The Microsoft templates really go to town when it comes to implementing variables and parameters. That level of detail isn't required here but it's hard to see just how much is required until the template is complete. My workflow involves using hard-coded values initially so the focus can remain on getting the template working and then refactoring later.
- Refactor the Template with Parameters, Variables and Functions. For me refactoring to remove the hard-coded values is one of most fun and rewarding parts of the process. There's a wealth of programming functionality available in ARM templates -- see here for all the details.
- Use the Template to Create Multiple VMs. We've proved the template can create a single VM -- what about multiple VMs? This section explores the options.
That's enough overview -- time to get stuck in!
Create a Model VM in Azure Portal
As above, the first VM we'll create using an ARM template is going to be called PRM-DAT-AIO in a resource group called PRM-DAT. In order to help build the template we'll create a model VM called PRM-DAT-AAA in a resource group called PRM-DAT via the Azure Portal. The procedure is as follows:
- Create a resource group called PRM-DAT in your preferred location -- in my case West Europe.
- Create a standard (Standard-LRS) storage account in the new resource group -- I named mine prmdataaastorageaccount. Don't enable diagnostics.
- Create a Windows Server 2012 R2 Datacenter VM (size right now doesn't matter much -- I chose Standard DS1 to keep costs down) called PRM-DAT-AAA based on the PRM-DAT resource group, the prmdataaastorageaccount storage account and the prmvirtualnetwork that was created at the beginning of this blog series as the common virtual network for all VMs. Don't enable monitoring.
- In Public IP addresses locate PRM-DAT-AAA and under configuration set the DNS name label to prm-dat-aaa.
- In Network security groups locate PRM-DAT-AAA and add the following tag: displayName : NetworkSecurityGroup.
- In Network interfaces locate PRM-DAT-AAAnnn (where nnn represents any number) and add the following tag: displayName : NetworkInterface.
- In Public IP addresses locate PRM-DAT-AAA and add the following tag: displayName : PublicIPAddress.
- In Storage accounts locate prmdataaastorageaccount and add the following tag: displayName : StorageAccount.
- In Virtual machines locate PRM-DAT-AAA and add the following tag: displayName : VirtualMachine.
You can now explore all the different parts of this VM in the Azure Resource Explorer. For example, the public IP address should look similar to:

Create a Visual Studio Solution
We'll be building and running our ARM template in Visual Studio. You may want to refer to previous posts (here and here) as a reminder for some of the configuration steps which are as follows:
- In the Web Portal navigate to your team project and add a new Git repository called Infrastructure.
- In Visual Studio clone the new repository to a folder called Infrastructure at your preferred location on disk.
- Create a new Visual Studio Solution (not project!) called Infrastructure one level higher then the Infrastructure folder. This effectively stops Visual Studio from creating an unwanted folder.
- Add .gitignore and .gitattributes files and perform a commit.
- Add a new Visual Studio Project to the solution of type Azure Resource Group called DeploymentTemplates. When asked to select a template choose anything.
- Delete the Scripts, Templates and Tools folders from the project.
- Add a new project to the solution of type PowerShell Script Project called DeploymentScripts.
- Delete Script.ps1 from the project.
- In the DeploymentTemplates project add a new Azure Resource Manager Deployment Project item called WindowsServer2012R2Datacenter.json (spaces not allowed).
- In the DeploymentScripts project add a new PowerShell Script item for the PowerShell that will create the PRM-DAT resource group with a PRM-DAT-AIO server -- I called my file Create PRM-DAT.ps1.
- Perform a commit and sync to get everything safely under version control.
With all that configuration you should have a Visual Studio solution looking something like this:

Perform an Initial Deployment
It's now time to write just enough code in Create PRM-DAT.ps1 to prove that we can initiate a deployment from PowerShell. First up is the code to authenticate to Azure PowerShell. I have the authentication code which was the output of this post wrapped in a function called Set-AzureRmAuthenticationForMsdnEnterprise which in turn is contained in a PowerShell module file called Authentication.psm1. This file in turn is deployed to C:\Users\Graham\Documents\WindowsPowerShell\Modules\Authentication which then allows me to call Set-AzureRmAuthenticationForMsdnEnterprise from anywhere on my development machine. (Although this function could clearly be made more generic with the use of some parameters I've consciously chosen not to so I can check my code in to GitHub without worrying about exposing any authentication details.) The initial contents of Create PRM-DAT.ps1 should end up looking as follows:
|
|
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise # Make sure we can get the root of the solution wherever it's installed to $solutionRoot = Split-Path -Path $MyInvocation.MyCommand.Definition -Parent # Always need the resource group to be present New-AzureRmResourceGroup -Name PRM-DAT -Location westeurope -Force # Deploy the contents of the template New-AzureRmResourceGroupDeployment -ResourceGroupName PRM-DAT ` -TemplateFile "$solutionRoot\..\DeploymentTemplates\WindowsServer2012R2Datacenter.json" ` -Force -Verbose |
Running this code in Visual Studio should result in a successful outcome, although admittedly not much has happened because the resource group already existed and the deployment template is empty. Nonetheless, it's progress!
Build the Deployment Template Resource by Resource Using Hard-coded Values
The first resource we'll code is a storage account. In the DeploymentTemplates project open WindowsServer2012R2Datacenter.json which as things stand just contains some boilerplate JSON for the different sections of the template that we'll be completing. What you should notice is the JSON Outline window is now available to assist with editing the template. Right-click resources and choose Add New Resource:

In the Add Resource window find Storage Account and add it with the name (actually the display name) of StorageAccount:

This results in boilerplate JSON being added to the template along with a variable for actual storage account name and a parameter for account type. We'll use a variable later but for now delete the variable and parameter that was added -- you can either use the JSON Outline window or manually edit the template.
We now need to edit the properties of the resource with actual values that can create (or update) the resource. In order to understand what to add we can use the Azure Resource Explorer to navigate down to the storageAccounts node of the MSDN subscription where we created prmdataaastorageaccount:

In the right-hand pane of the explorer we can see the JSON that represents this concrete resource, and although the properties names don't always match exactly it should be fairly easy to see how the ‘live' values can be used as a guide to populating the ones in the deployment template:

So, back to the deployment template the following unassigned properties can be assigned the following values:
- "name": "prmdataiostorageaccount"
- "location": "West Europe"
- "accountType": "Standard_LRS"
The resulting JSON should be similar to:
|
|
{ "name": "prmdataiostorageaccount", "type": "Microsoft.Storage/storageAccounts", "location": "West Europe", "apiVersion": "2015-06-15", "dependsOn": [ ], "tags": { "displayName": "StorageAccount" }, "properties": { "accountType": "Standard_LRS" } } |
Save the template and switch to Create PRM-DAT.ps1 to run the deployment script which should create the storage account. You can verify this either via the portal or the explorer.
The next resource we'll create is a NetworkSecurityGroup, which has an extra twist in that at the time of writing adding it to the template isn't supported by the JSON Outline window. There's a couple of ways to go here -- either type the JSON by hand or use the Create function in the Azure Resource Explorer to generate some boilerplate JSON. This latter technique actually generates more JSON than is needed so in this case is something of a hindrance. I just typed the JSON directly and made use of the IntelliSense options in conjunction with the PRM-DAT-AAA network security group values via the Azure Resource Explorer. The JSON that needs adding is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ "name": "PRM-DAT-AIO", "type": "Microsoft.Network/networkSecurityGroups", "location": "West Europe", "apiVersion": "2015-06-15", "tags": { "displayName": "NetworkSecurityGroup" }, "properties": { "securityRules": [ { "name": "default-allow-rdp", "properties": { "protocol": "Tcp", "sourcePortRange": "*", "destinationPortRange": "3389", "sourceAddressPrefix": "*", "destinationAddressPrefix": "*", "access": "Allow", "priority": 1000, "direction": "Inbound" } } ] } } |
Note that you'll need to separate this resource from the storage account resource with a comma to ensure the syntax is valid. Save the template, run the deployment and refresh the Azure Resource Explorer. You can now compare the new PRM-DAT-AIO and PRM-DAT-AAA network security groups in the explorer to validate the JSON that creates PRM-DAT-AIO. Note that by zooming out in your browser you can toggle between the two resources and see that it is pretty much just the etag values that are different.
The next resource to add is a public IP address. This can be added from the JSON Outline window using PublicIPAddress as the name but it also wants to add a reference to itself to a network interface which in turn wants to reference a virtual network. We are going to use an existing virtual network but we do need a network interface, so give the new network interface a name of NetworkInterface and the new virtual network can be any temporary name. As soon as the new JSON components have been added delete the virtual network and all of the variables and parameters that were added. All this makes sense when you do it -- trust me!
Once edited with the appropriate values the JSON for the public IP address should be as follows:
|
|
{ "name": "PRM-DAT-AIO", "type": "Microsoft.Network/publicIPAddresses", "location": "West Europe", "apiVersion": "2015-06-15", "tags": { "displayName": "PublicIPAddress" }, "properties": { "publicIPAllocationMethod": "Dynamic", "dnsSettings": { "domainNameLabel": "prm-dat-aio" } } } |
The edited JSON for the network interface should look similar to the code that follows, but note I've replaced my MSDN subscription GUID with an ellipsis.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
{ "name": "prm-dat-aio123", "type": "Microsoft.Network/networkInterfaces", "location": "West Europe", "apiVersion": "2015-06-15", "dependsOn": [ "[concat('Microsoft.Network/publicIPAddresses/', 'PRM-DAT-AIO')]", "[concat('Microsoft.Network/networkSecurityGroups/', 'PRM-DAT-AIO')]" ], "tags": { "displayName": "NetworkInterface" }, "properties": { "ipConfigurations": [ { "name": "ipconfig1", "properties": { "privateIPAllocationMethod": "Dynamic", "subnet": { "id": "/subscriptions/.../resourceGroups/PRM-COMMON/providers/Microsoft.Network/virtualNetworks/prmvirtualnetwork/subnets/default" }, "publicIPAddress": { "id": "/subscriptions/.../resourceGroups/PRM-DAT/providers/Microsoft.Network/publicIPAddresses/PRM-DAT-AIO" } } } ], "networkSecurityGroup": { "id": "/subscriptions/.../resourceGroups/PRM-DAT/providers/Microsoft.Network/networkSecurityGroups/PRM-DAT-AIO" } } } |
It's worth remembering at this stage that we're hard-coding references to other resources. We'll fix that up later on, but for the moment note that the network interface needs to know what virtual network subnet it's on (created in an earlier post), and which public IP address and network security group it's using. Also note the dependsOn section which ensures that these resources exist before the network interface is created. At this point you should be able to run the deployment and confirm that the new resources get created.
Finally we can add a Windows virtual machine resource. This is supported from the JSON Outline window, however this resource wants to reference a storage account and virtual network. The storage account exists and that should be selected, but once again we'll need to use a temporary name for the virtual network and delete it and the variables and parameters. Name the virtual machine resource VirtualMachine. Edit the JSON with appropriate hard-coded values which should end up looking as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
{ "name": "PRM-DAT-AIO", "type": "Microsoft.Compute/virtualMachines", "location": "West Europe", "apiVersion": "2015-06-15", "dependsOn": [ "[concat('Microsoft.Storage/storageAccounts/', 'prmdataiostorageaccount')]", "[concat('Microsoft.Network/networkInterfaces/', 'prm-dat-aio123')]" ], "tags": { "displayName": "VirtualMachine" }, "properties": { "hardwareProfile": { "vmSize": "Standard_DS1" }, "osProfile": { "computerName": "PRM-DAT-AIO", "adminUsername": "prmadmin", "adminPassword": "Mystrongpasswordhere9" }, "storageProfile": { "imageReference": { "publisher": "MicrosoftWindowsServer", "offer": "WindowsServer", "sku": "2012-R2-Datacenter", "version": "latest" }, "osDisk": { "name": "PRM-DAT-AIO", "vhd": { "uri": "https://prmdataiostorageaccount.blob.core.windows.net/vhds/PRM-DAT-AIO.vhd" }, "caching": "ReadWrite", "createOption": "FromImage" } }, "networkProfile": { "networkInterfaces": [ { "id": "/subscriptions/.../resourceGroups/PRM-DAT/providers/Microsoft.Network/networkInterfaces/prm-dat-aio123" } ] } } } |
Running the deployment now should result in a complete working VM which you can remote in to.
The final step before going any further is to tear-down the PRM-DAT resource group and check that a fully-working PRM-DAT-AIO VM is created. I added a Destroy PRM-DAT.ps1 file to my DeploymentScripts project with the following code:
|
|
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise # Deletes all resources in the resource group!! Remove-AzureRmResourceGroup -Name PRM-DAT -Force |
Refactor the Template with Parameters, Variables and Functions
It's now time to make the template reusable by refactoring all the hard-coded values. Each situation is likely to vary but in this case my specific requirements are:
- The template will always create a Windows Server 2012 R2 Datacenter VM, but obviously the name of the VM needs to be specified.
- I want to restrict my VMs to small sizes to keep costs down.
- I'm happy for the VM username to always be the same so this can be hard-coded in the template, whilst I want to pass the password in as a parameter.
- I'm adding my VMs to an existing virtual network in a different resource group and I'm making a concious decision to hard-code these details in.
- I want the names of all the different resources to be generated using the VM name as the base.
These requirements gave rise to the following parameters, variables and a resource function:
- nodeName parameter -- this is used via variable conversions throughout the template to provide consistent naming of objects. My node names tend to be of the format used in this post and that's the only format I've tested. Beware if your node names are different as there are naming rules in force.
- nodeNameToUpper variable -- used where I want to ensure upper case for my own naming convention preferences.
- nodeNameToLower variable -- used where lower case is a requirement of ARM eg where nodeName forms part of a DNS entry.
- vmSize parameter -- restricts the template to creating VMs that are not going to burn Azure credits too quickly and which use standard storage.
- storageAccountName variable -- creates a name for the storage account that is based on a lower case nodeName.
- networkInterfaceName variable -- creates a name for the network interface based on a lower case nodeName with a number suffix.
- virtualNetworkSubnetName variable -- used to create the virtual network subnet which exists in a different resource group and requires a bit of construction work.
- vmAdminUsername variable -- creates a username for the VM based on the nodeName. You'll probably want to change this.
- vmAdminPassword parameter -- the password for the VM passed-in as a secure string.
- resourceGroup().location resource function -- neat way to avoid hard-coding the location in to the template.
Of course, these refactorings shouldn't affect the functioning of the template, and tearing down the PRM-DAT resource group and recreating it should result in the same resources being created.
What about Environments where Multiple VMs are Required?
The work so far has been aimed at creating just one VM, but what if two or more VMs are needed? It's a very good question and there are at least two answers. The first involves using the template as-is and calling New-AzureRmResourceGroupDeployment in a PowerShell Foreach loop. I've illustrated this technique in Create PRM-DQA.ps1 in the DeploymentScripts project. Whilst this works very nicely the VMs are created in series rather than in parallel and, well, who wants to wait? My first thought at creating VMs in parallel was to extend the Foreach loop idea with the -parallel switch in a PowerShell workflow. The code which I was hoping would work looks something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
workflow Create-WindowsServer2012R2Datacenter { param ([string[]] $vms, [string] $resourceGroupName, [string] $solutionRoot) Foreach -parallel($vm in $vms) { # Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise New-AzureRmResourceGroupDeployment -ResourceGroupName $resourceGroupName ` -TemplateFile "$solutionRoot\..\DeploymentTemplates\WindowsServer2012R2Datacenter.json" ` -Force ` -Verbose ` -Mode Incremental ` -TemplateParameterObject @{ nodeName = $vm; vmSize = 'Standard_DS1'; vmAdminPassword = 'MySuperSecurePassword' } } } $resourceGroupName = 'PRM-PRD' New-AzureRmResourceGroup -Name $resourceGroupName -Location westeurope -Force $virtualmachines = "$resourceGroupName-SQL", "$resourceGroupName-IIS" Create-WindowsServer2012R2Datacenter -vms $virtualmachines -resourceGroupName $resourceGroupName -solutionRoot $PSScriptRoot |
Unfortunately it seems like this idea is a dud -- see here for the details. Instead the technique appears to be to use the copy, copyindex and length features of ARM templates as documented here. This necessitates a minor re-write of the template to pass in and use an array of node names, however there are complications where I've used variables to construct resource names. At the time of publishing this post I'm working through these details -- keep an eye on my GitHub repository for progress.
Wrap-Up
Before actually wrapping-up I'll make a quick mention of the template's outputs node. A handy use for this is debugging, for example where you are trying to construct a complicated variable and want to check its value. I've left an example in the template to illustrate.
I'll finish this post with a question that I've been pondering as I've been writing this post, which is whether just because we can create and configure VMs at the push of a button does that mean we should create and configure new VMs every time we deploy our application? My thinking at the moment is probably not because of the time it will add but as always it depends. If you want a clean start every time you deploy then you certainly have that option, but my mind is already thinking ahead to the additional amount of time it's going to take to actually configure these VMs with IIS and SQL Server. Never say never though, as who knows what's in store for the future? As Azure (presumably) gets faster and VMs become more lightweight with the arrival of Nano Server perhaps creating and configuring VMs from scratch as part of the deployment pipeline will be so fast that there would be no reason not to. Or maybe we'll all be using containers by then...
Cheers -- Graham
Continuous Delivery with TFS / VSTS – A Lap Around the Contoso University Sample Application
In the previous post in this series on Continuous Delivery with TFS / VSTS we configured a sample application for Git in Visual Studio 2015. This post continues with that configuration and also examines some of the more interesting parts of Contoso University before firing it up and taking it for a spin.
Build and Update NuGets
Picking up from where we left off last time in Visual Studio, Team Explorer -- Home should be displaying ContosoUniversity.sln in the Solutions section. Double-click this to open Contoso University and navigate to Solution Explorer. The first thing to do is to hit F6 to build the solution. NuGet packages should be restored and the five projects should build. It's worth checking Team Explorer -- Changes at this point to make sure .gitignore is doing its job properly -- if it is there should be no changes as far as version control is concerned.
For non-production applications I usually like to keep bang up-to-date with the latest NuGets so in Solution Explorer right click the solution and choose Manage NuGet Packages for Solution. Click on the Updates link and allow the manager to do its thing. If any updates are found click to Select all packages and then Update:

Commit (and sync if you like) these changes (see the previous post for a reminder of the workflow for this) and check the solution still builds.
Test the Unit Tests
The solution contains a couple of unit tests as well as some UI tests. In order to just establish that the unit tests work at this stage open Test Explorer (Test > Windows > Test Explorer) and then click on the down arrow next to Playlist : All Tests. Choose Open Playlist File, open ...\ContosoUniversity.Web.UnitTests\UnitTests.playlist and run the tests which should pass, albeit with very poor coverage (Tests > Analyze Code Coverage > All Tests).
Code Analysis
Code analysis (a feature formerly known as FxCop) is enabled for every project and reports on any rule violations. I've set projects to use the Microsoft Managed Recommended Rules (note though that rule sets don't exist for SQL Server database Projects and in the case of ContosoUniversity.Database everything is selected) however the code as it exists in GitHub doesn't violate any of those rules. To see this feature in action right-click the ContosoUniversity.Web project and choose Properties. On the Code Analysis tab change the rule set to Microsoft All Rules and build the solution. The Error List window should appear and there should be quite a few warnings -- 85 at the time of writing this post. Reverse the change and the solution should once again build without warnings.
SQL Server Data Tools -- A Better Way to Manage Database Changes
There are several ways to manage the schema changes for an application's database and whilst every technique undoubtedly has its place the one I recommend for most scenarios is the declarative approach. The simple explanation is that code files declare how you want the database to look and then a separate ‘engine' has the task of figuring out a script which will make a blank or existing database match the declaration. It's not a magic bullet since it doesn't cope with all scenarios out-of-the-box however there is usually a way to code around the trickier situations. I explained how I converted Contoso University from an Entity Framework Code Migrations way of managing database changes to a declarative one using SQL Server Data Tools here. If you are new to SSDT and want to learn about it I have a Getting Started post here.
As far as Visual Studio solutions are concerned, the declarative approach using SSDT is delivered by way of SQL Server Database Projects. In Contoso University this is the ContosoUniversity.Database project. This contains CREATE scripts for tables and stored procedures as well as for permissions and security. Not only does it contain scripts that represent the database schema, it also contains scripts that can insert reference data in to a newly created database. The significance of this becomes apparent when you realise that a database project can be used to create a database in LocalDB, which can be made fully functioning by inserting reference data. In many cases this could remove the need for a ‘dev' environment, as the local workstation is the dev environment, database and all. This eliminates the problem of config files containing connection strings specific to developers (and the check-in problems that this can cause) because the connection string for LocalDB is generic. This way of working has the potential to wave goodbye to situations where getting an application working on a development machine requires a lengthy setup script and usually some magic.
To see this in action, within the ContosoUniversity.Database project right-click CU-DEV.publish.xml and choose Publish. In the Publish Database CU-DEV.publish.xml dialog click on Publish:

Now make sure that the ContosoUniversity.Web project is set as the startup project (if not in bold right-click and choose Set as StartUp Project) and hit F5 to run the application. A fully functioning ContosoUniversity should spring to life. Navigating to (for example) Departments should allow you to perform all CRUD activities. How's that for simplicity?
Tour Stops Here
That's it for our tour of Contoso University. Although there are automated UI tests in the solution I'm purposefully not covering them here as they are very much an advanced topic and I'm also planning some changes. That said, if you have FireFox installed on your development machine you can probably make them run. See my post in a previous blog series here.
In the next post we look at getting a basic CI build up-an-running. Happy coding until then!
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Configuring a Sample Application for Git in Visual Studio 2015
In this instalment of my blog post series on Continuous Delivery with TFS / VSTS we configure a sample application to work with Git in Visual Studio 2015 and perform our first commit. This post assumes that nothing has changed since the last post in the series.
Configure Git in Visual Studio 2015
In order to start working with Git in Visual Studio there are some essential and non-essential settings to configure. From the Team Explorer -- Home page choose Settings > Git > Global Settings. Visual Studio will have filled in as many settings as possible and the panel will look similar to this:

Complete the form as you see fit. The one change I make is to trim Repos from the Default Repository Location (to try and reduce max filepath issues) and then from Windows Explorer create the Source folder with child folders named GitHub, TFS and VSTS. This way I can keep repositories from the different Git hosts separate and avoid name clashes if I have a repository named the same in different hosts.
Clone the Repository
In the previous post we created ContosoUniversity (the name of the sample application we'll be working with) repositories in both TFS and VSTS. Before we go any further we need to clone the ContosoUniversity repository to our development workstation.
If you are working with TFS we finished-up last time with the Team Explorer -- Home page advising that we must clone the repository. However, at the time of writing Visual Studio 2015.1 seemed to have bug (TFS only) where it was still remembering the PRM repository that we deleted and wasn't allowing the ContosoUniversity repository to be cloned. Frustratingly, after going down several blind avenues the only way I found to fix this was to temporarily recreate the PRM repository from the Web Portal. With this done clicking on the Manage Connections icon on the Team Explorer toolbar now shows the ContosoUniversity repository:

Double-click the repository which will return you to the Team Explorer home page with links to clone the repository. Clicking one of these links now shows the Clone Repository details with the correct remote settings:

Make sure you change the local settings to the correct folder structure (if you are following my convention this will be ...\Source\TFS\ContosoUniversity) and click on Clone. Finally, return to the Web Portal and delete the PRM repository.
The procedure for cloning the ContosoUniversity repository if you are working with VSTS is similar but without the bug. However in the previous post we hadn't got as far as connecting VSTS to Visual Studio. The procedure for doing this is the same as for TFS however when you get to the Add Team Foundation Server dialog you need to supply the URI for your VSTS subscription rather than the TFS instance name:

With your VSTS subscription added you will eventually end up back at the Team Explorer -- Home page where you can clone the repository as for TFS but with a local path of ...\Source\VSTS\ContosoUniversity.
Add the Contoso University Sample Application
The Contoso University sample application I use is an ASP.NET MVC application backed by a a SQL Server database. It's origins are the MVC Getting Started area of Microsoft's www.asp.net site however I've made a few changes in particular to how the database side of things is managed. I'll be explaining a bit more about all this in a later post but for now you can download the source code from my GitHub repository here using the Download ZIP button. Once downloaded unblock the file and extract the contents.
One of they key things about version control -- and Git in particular -- is that you want to avoid polluting it with files that are not actually part of the application (such as Visual Studio settings files) or files that can be recreated from the source code (such as binaries). There can be lots of this stuff but handily Git provides a solution by way of the .gitignore file and Microsoft adds icing to the cake by providing a version specifically tailored to Visual Studio. Although the sample code from my GitHub repository contains a .gitignore I've observed odd behaviours if this file isn't part of the repository before an existing Visual Studio solution is added so my technique is to add it first. From Team Explorer -- Home navigate to Settings > Git > Repository Settings. From there click on the Add links to add an ignore file and an attributes file:
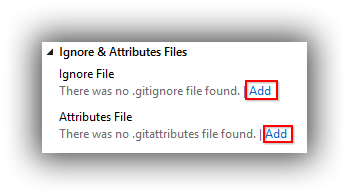
Switch back to Team Explorer -- Home and click on Changes. These two files should appear under Included Changes. Supply a commit message and from the Commit dropdown choose Commit and Sync:

Now switch back to Windows Explorer and the extracted Contoso University, and drill down to the folder that contains ContosoUniversity.sln. Delete .gitattributes and .gitignore and then copy the contents of this folder to ...\Source\TFS\ContosoUniversity or ...\Source\VSTS\ContosoUniversity depending on which system you are using. You should end up with ContosoUniversity.sln in the same folder as .gitattributes and .gitignore.
Back over to Visual Studio and the Team Explorer -- Changes panel and you should see that there are Untracked Files:

Click on Add All and then Commit and Sync these changes as per the procedure described above.
That's it for this post. Next time we open up the Contoso University solution and get it configured to run.
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Creating a Team Project and Git Repository
In the previous post in this blog series on Continuous Delivery with TFS / VSTS we looked at how to commission either TFS or VSTS. In this seventh post in the series we continue from where we left off by creating a Team Project and then within that team project the Git repository that will hold the source code of our sample application. Before we do all that though we'll want to commission a developer workstation in Azure.
Commission a Developer Workstation
Although it's possible to connect an on premises developer workstation to either VSTS (straightforward) or our TFS instance (a bit trickier) to keep things realistic I prefer to create a Windows 10 VM in Azure that is part of the domain. Use the following guide to set up such a workstation:
- If you are manually creating a VM in the portal it's not wholly clear where to find Windows 10 images. Just search for 10 though and they will appear at the top of the list. I chose Windows 10 Enterprise (x64) -- make sure you select to create in Resource Manager. (Although you can choose an image with Visual Studio already installed I prefer not to so I can have complete control.)
- I created my VM as a Standard DS3 on premium storage in my PRM-CORE resource group, called PRM-CORE-DEV. Make sure you choose the domain's virtual network and the premium storage account.
- With the VM created log in and join the domain in the normal way. Install any Windows Updates but note that since this in an Enterprise edition of Windows you will be stuck with the windows version that the image was created with. For me this was version 10.0 (build 10240) even though the latest version is 1511 (build 10586) (run winver at a command prompt to get your version). I've burned quite a few hours trying to upgrade 10.0 to 1511 (using the 1511 ISO) with no joy -- I think this is because Azure doesn't support in-place upgrades.
- Install the best version of Visual Studio 2015 available to you (for me it's the Enterprise edition) and configure as required. I prefer to register with a licence key as well as logging in with my MSDN account from Help > Register Product.
- Install any updates from Tools > Extensions and Updates.
Create a Team Project
The procedure for creating a Team Project differs depending on whether you are using VSTS or TFS. If you are using VSTS simply navigate to the Web Portal home page of your subscription and select New:

This will bring up the Create New Team Project window where you can specify your chosen settings (I'm creating a project called PRM using the Scrum process template and using Git version control):

Click on Create project which will do as it suggests. That button then turns in to a Navigate to project button.
If on the other hand you are using TFS you need to create a team project from within Visual Studio since a TFS project may have other setup work to perform for SSRS and SharePoint that doesn't apply to VSTS. The first step is to connect to TFS by navigating to Team Explorer and choosing the green Manage Connections button on the toolbar. This will display a Manage Connections link which in tun will bring up a popup menu allowing you to Connect to Team Project:

This brings up the Connect to Team Foundation Server dialog where you need to click the Servers button:

This will bring up the Add/Remove Team Foundation Server dialog where you need to click the Add button:

Finally we get to the Add Team Foundation Server dialog where we can add details of our TFS instance:

As long as you are using the standard path, port number and protocol you can simply type the server name and the dialog will build and display the URI in the Preview box. Click OK and work your way back down to the Connect to Team Foundation Server dialog where you can now connect to your TFS instance:

Ignore the message about Configure your workspace mappings (I chose Don't prompt again) and instead click on Home > Projects and My Teams > New Team Project:

This brings up a wizard to create a new team project. As with VSTS, I created a project called PRM using the Scrum process template and using Git version control. The finishing point of this process is a Team Explorer view that advises that You must clone the repository to open solutions for this project. Don't be tempted since there is another step we need to take!
Create a Repository with a Name of our Choosing
As things stand both VSTS and TFS have initialised the newly minted PRM team projects with a Git repository named PRM. In some cases this may be what you want (where the team project name is the same as the application for example) however that's not the case here since our application is called Contoso University. We'll be taking a closer look at Contoso University in the next post in this series but for now we just need to create a repository with that name. (In later posts we'll be creating other repositories in the PRM team project to hold different Visual Studio solutions.)
The procedure is the same for both VSTS and TFS. Start by navigating to the Web Portal home page for either VSTS or TFS and choose Browse under Recent projects & teams. Navigate to your team project and click on the Code link:

This takes you to the Code tab which will entice you to Add some code!. Resist and instead click on the down arrow next to the PRM repository and then click on New repository:

In the window that appears create a new Git repository called ContosoUniversity (no space).
In the interests of keeping things tidy we should delete the PRM repository so click the down arrow next to (the now selected) ContosoUniversity repository and choose Manage repositories. This takes you to the Version Control tab of the DefaultCollection‘s Control Panel. In the Repositories panel click on the down arrow next to the PRM repository and choose Delete repository:

And that's it! We're all set up for the next post in this series where we start working with the Contoso University sample application.
Cheers -- Graham











































