Continuous Delivery with Containers – Use Visual Studio Team Services and Docker to Build and Deploy ASP.NET Core to Linux
In this blog series on Continuous Delivery with Containers I'm documenting what I've learned about Docker and containers (both the Linux and Windows variety) in the context of continuous delivery with Visual Studio Team Services. The Docker and containers world is mostly new to me and I have only the vaguest idea of what I'm doing so feel free to let me know in the comments if I get something wrong.
Although the Windows Server Containers feature is now a fully supported part of Windows it is still extremely new in comparison to containers on Linux. It's not surprising then that even in the world of the Visual Studio developer the tooling is most mature for deploying containers to Linux and that I chose this as my starting point for doing something useful with Docker. As I write this the documentation for deploying containers with Visual Studio Team Services is fragmented and almost non-existent. The main references I used for this post were:
However to my mind none of these blogs cover the whole process to any satisfactory depth and in any case they are all somewhat out of date. In this post I've therefore tried to piece all of the bits of the jigsaw together that form the end-to-end process of creating an ASP.NET Core app in Visual Studio and debugging it whilst running on Linux, all the way through to using VSTS to deploy the app in a container to a target node running Linux. I'm not attempting to teach the basics of Docker and containers here and if you need to get up to speed with this see my Getting Started post here.
Install the Tooling for the Visual Studio Development Inner Loop
In order to get your development environment properly configured you'll need to be running a version of Windows that is supported by Docker for Windows and have the following tooling installed:
You'll also need a VSTS account and an Azure subscription.
Create an ASP.NET Core App
I started off by creating a new Team Project in VSTS and called Containers and then from the Code tab creating a New repository using Git called AspNetCoreLinux:

Over in Visual Studio I then cloned this repository to my source control folder (in my case to C:\Source\VSTS\AspNetCoreLinux as I prefer a short filepath) and added .gitignore and .gitattributes files (see here if this doesn't make sense) and committed and synced the changes. Then from File > New > Project I created an ASP.NET Core Web Application (.NET Core) application called AspNetCoreLinux using the Web Application template (not shown):

Visual Studio will restore the packages for the project after which you can run it with F5 or Ctrl+F5.
The next step is to install support for Docker by right-clicking the project and choosing Add > Docker Support. You should now see that the Run dropdown has an option for Docker:

With Docker selected and Docker for Windows running (with Shared Drives enabled!) you will now be running and debugging the application in a Linux container. For more information about how this works see the resources on the Visual Studio Tools for Docker site or my list of resources here. Finally, if everything is working don't forget to commit and sync the changes.
Provision a Linux Build VM
In order to build the project in VSTS we'll need a build machine. We'll provision this machine in Azure using the Azure driver for Docker Machine which offers a very neat way for provisioning a Linux VM with Docker installed in Azure. You can learn more about Docker Machine from these sources:
To complete the following steps you'll need the Subscription ID of the Azure subscription you intend to use which you can get from the Azure portal.
- At a command prompt enter the following command:
|
|
docker-machine create -d azure --azure-subscription-id adb4a497-7e0b-querty-ab9c-e4a160567809 --azure-static-public-ip --azure-open-port 80 --azure-resource-group VstsBuildDeployRG vstsbuildvm |
By default this will create a Standard A2 VM running Ubuntu called vstsbuildvm (note that "Container names must be 3-63 characters in length and may contain only lower-case alphanumeric characters and hyphen. Hyphen must be preceded and followed by an alphanumeric character.") in a resource group called VstsBuildDeployRG in the West US datacentre (make sure you use your own Azure Subscription ID). It's fully customisable though and you can see al the options here. In particular I've added the option for the VM to be created with a static public IP address as without that there's the possibility of certificate problems when the VM is shut down and restarted with a different IP address.
- Azure now wants you to authenticate. The procedure is explained in the output of the command window, and requires you to visit https://aka.ms/devicelogin and enter the one-time code:

Docker Machine will then create the VM in Azure and configure it with Docker and also generate certificates at C:\Users\<yourname>\.docker\machine. Do have a poke a round the subfolders of this path as some of the files are needed later on and it will also help to understand how connections to the VM are handled.
- This step isn't strictly necessary right now, but if you want to run Docker commands from the current command prompt against the Docker Engine running on the new VM you'll need to configure the shell by first running docker-machine env vstsbuildvm. This will print out the environment variables that need setting and the command (@FOR /f "tokens=*" %i IN (‘docker-machine env vstsbuilddeployvm') DO @%I) to set them. These settings only persist for the life of the command prompt window so if you close it you'll need to repeat the process.
- In order to configure the internals of the VM you need to connect to it. Although in theory you can use the docker-machine ssh vstsbuildvm command to do this in practice the shell experience is horrible. Much better is to use a tool like PuTTY. Donovan Brown has a great explanation of how to get this working about half way down this blog post. Note that the folder in which the id_rsa file resides is C:\Users\<yourname>\.docker\machine\machines\<yourvmname>. A tweak worth making is to set the DNS name for the server as I describe in this post so that you can use a fixed host name in the PuTTY profile for the VM rather than an IP address.
- With a connection made to the VM you need to issue the following commands to get it configured with the components to build an ASP.NET Core application:
- Upgrade the VM with sudo apt-get update && sudo apt-get dist-upgrade.
- Install .NET Core following the instructions here, making sure to use the instructions for Ubuntu 16.04.
- Install npm with sudo apt -y install npm.
- Install Bower with sudo npm install -g bower.
- Next up is installing the VSTS build agent for Linux following the instructions for Team Services here. In essence (ie do make sure you follow the instructions) the steps are:
- Create and switch to a downloads folder using mkdir Downloads && cd Downloads.
- At the Get Agent page in VSTS select the Linux tab and the Ubuntu 16.04-x64 option and then the copy icon to copy the URL download link to the clipboard:

- Back at the PuTTY session window type sudo wget followed by a space and then paste the URL from the clipboard. Run this command to download the agent to the Downloads folder.
- Go up a level using cd .. and then make and switch to a folder for the agent using mkdir myagent && cd myagent.
- Extract the compressed agent file to myagent using tar zxvf ~/Downloads/vsts-agent-ubuntu.16.04-x64-2.108.0.tar.gz (note the exact file name will likely be different).
- Install the Ubuntu dependencies using sudo ./bin/installdependencies.sh.
- Configure the agent using ./config.sh after first making sure you have created a personal access token to use. I created my agent in a pool I created called Linux.
- Configure the agent to run as a service using sudo ./svc.sh install and then start it using sudo ./svc.sh start.
If the procedure was successful you should see the new agent showing green in the VSTS Agent pools tab:

Provision a Linux Target Node VM
Next we need a Linux VM we can deploy to. I used the same syntax as for the build VM calling the machine vstsdeployvm:
|
|
docker-machine create -d azure --azure-subscription-id adb4a497-7e0b-querty-ab9c-e4a160567809 --azure-static-public-ip --azure-open-port 80 --azure-resource-group VstsBuildDeployRG vstsdeployvm |
Apart from setting the DNS name for the server as I describe in this post there's not much else to configure on this server except for updating it using sudo apt-get update && sudo apt-get dist-upgrade.
Gearing Up to Use the Docker Integration Extension for VSTS
Configuration activities now shift over to VSTS. The first thing you'll need to do is install the Docker Integration extension for VSTS from the Marketplace. The process is straightforward and wizard-driven so I won't document the steps here.
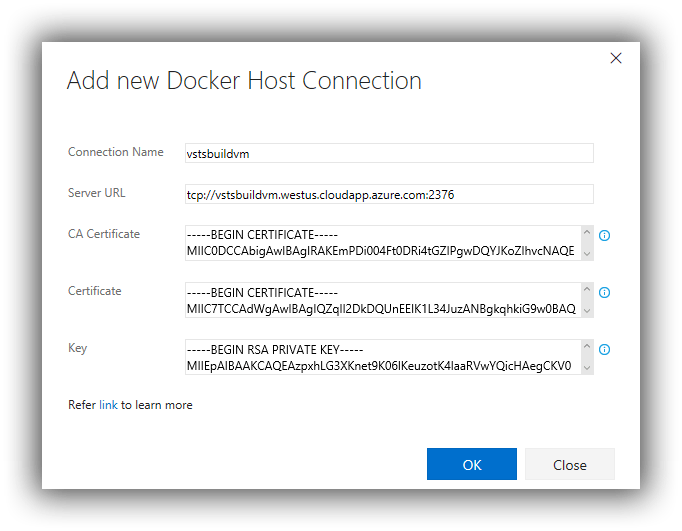
Next up is creating three service end points -- two of the Docker Host type (ie our Linux build and deploy VMs) and one of type Docker Registry. These are created by selecting Services from the Settings icon and then Endpoints and then the New Service Endpoint dropdown:

To create a Docker Host endpoint:
- Connection Name = whatever suits -- I used the name of my Linux VM.
- Server URL = the DNS name of the Linux VM in the format tcp://your.dns.name:2376.
- CA Certificate = contents of C:\Users\<yourname>\.docker\machine\machines\<yourvmname>\ca.pem.
- Certificate = contents of C:\Users\<yourname>\.docker\machine\machines\<yourvmname>\cert.pem.
- Key = contents of C:\Users\<yourname>\.docker\machine\machines\<yourvmname>\key.pem.
The completed dialog (in this case for the build VM) should look similar to this:

Repeat this process for the deploy VM.
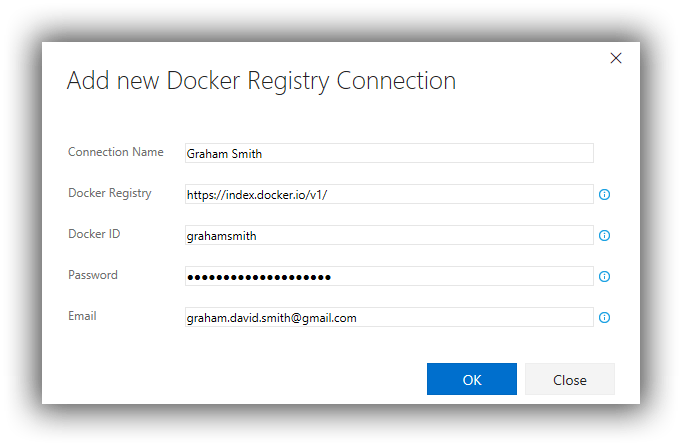
Next, if you haven't already done so you will need to create an account at Docker Hub. To create the Docker Registry endpoint:
- Connection Name = whatever suits -- I used my name
- Docker Registry = https://index.docker.io/v1/
- Docker ID = username for Docker Hub account
- Password = password for Docker Hub account
The completed dialog should look similar to this:

Putting Everything Together in a Build
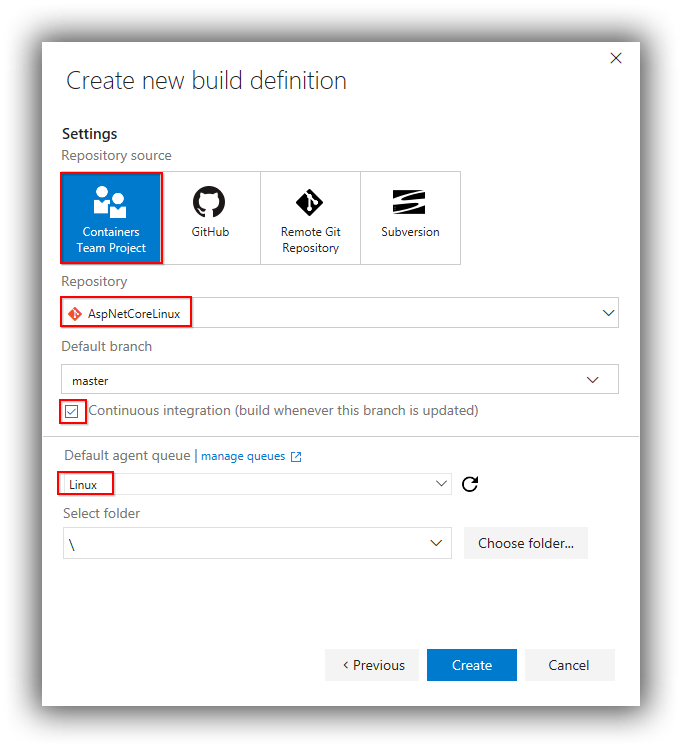
Now the fun part begins. To keep things simple I'm going to run everything from a single build, however in a more complex scenario I'd use both a VSTS build and a VSTS release definition. From the VSTS Build & Release tab create a new build definition based on an Empty template. Use the AspNetCoreLinux repository, check the Continuous integration box and select Linux for the Default agent queue (assuming you create a queue named Linux as I've done):

Using Add build step add two Command Line tasks and three Docker tasks:

In turn right-click all but the first task and disable them -- this will allow the definition to be saved without having to complete all the tasks.
The configuration for Command Line task #1 is:
- Tool = dotnet
- Arguments = restore -v minimal
- Advanced > Working folder = src/AspNetCoreLinux (use the ellipsis to select)
Save the definition (as AspNetCoreLinux) and then queue a build to make sure there are no errors. This task restores the packages specified in project.json.
The configuration for Command Line task #2 is:
- Tool = dotnet
- Arguments = publish -c $(Build.Configuration) -o $(Build.StagingDirectory)/app/
- Advanced > Working folder = src/AspNetCoreLinux (use the ellipsis to select)
Enable the task and then queue a build to make sure there are no errors. This task publishes the application to$(Build.StagingDirectory)/app (which equates to home/docker-user/myagent/_work/1/a/app).
The configuration for Docker task #1 is:
- Docker Registry Connection = <name of your Docker registry connection>
- Action = Build an image
- Docker File = $(Build.StagingDirectory)/app/Dockerfile
- Build Context = $(Build.StagingDirectory)/app
- Image Name = <your Docker ID>/aspnetcorelinux:$(Build.BuildNumber)
- Docker Host Connection = vstsbuildvm (or your Docker Host name for the build server)
- Working Directory = $(Build.StagingDirectory)/app
Enable the task and then queue a build to make sure there are no errors. If you run sudo docker images on the build machine you should see the image has been created.
The configuration for Docker task #2 is:
- Docker Registry Connection = <name of your Docker registry connection>
- Action = Push an image
- Image Name = <your Docker ID>/aspnetcorelinux:$(Build.BuildNumber)
- Advanced Options > Docker Host Connection = vstsbuildvm (or your Docker Host name for the build server)
- Advanced Options > Working Directory = $(System.DefaultWorkingDirectory)
Enable the task and then queue a build to make sure there are no errors. If you log in to Docker Hub you should see the image under your profile.
The configuration for Docker task #3 is:
- Docker Registry Connection = <name of your Docker registry connection>
- Action = Run an image
- Image Name = <your Docker ID>/aspnetcorelinux:$(Build.BuildNumber)
- Container Name = aspnetcorelinux$(Build.BuildNumber) (slightly different from above!)
- Ports = 80:80
- Advanced Options > Docker Host Connection = vstsdeployvm (or your Docker Host name for the deploy server)
- Advanced Options > Working Directory = $(System.DefaultWorkingDirectory)
Enable the task and then queue a build to make sure there are no errors. If you navigate to the URL of your deployment sever (eg http://vstsdeployvm.westus.cloudapp.azure.com/) you should see the web application running. As things stand though if you want to deploy again you'll need to stop the container first.
That's all for now...
Please do be aware that this is only a very high-level run-through of this toolchain and there many gaps to be filled: how does a website work with databases, how to host a website on something other than the Kestrel server used here and how to secure containers that should be private are just a few of the many questions in my mind. What's particularly exciting though for me is that we now have a great solution to the problem of developing a web app on Windows 10 but deploying it to Windows Server, since although this post was about Linux, Docker for Windows supports the same way of working with Windows Server Core and Nanao Server (currently in beta). So I hope you found this a useful starting point -- do watch out for my next post in this series!
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Instrument for Telemetry with Application Insights
If you get to the stage where you are deploying your application on a very frequent basis and you are relying on automated tests for the bulk of your quality assurance then a mechanism to alert you when things go wrong in production is essential. There are many excellent tools that can help with this however anyone working working with ASP.NET websites (such as the one used in this blog series) and who has access to Azure can get going very quickly using Application Insights. I should qualify that by saying that whilst it is possible to get up-and-running very quickly with Application Insights there is a bit more work to do to make Application Insights a useful part of a continuous delivery pipeline. In this post in my blog series on Continuous Delivery with TFS / VSTS we take a look at doing just that!
The Big Picture
My aim in this post is to get telemetry from the Contoso University sample ASP.NET application running a) on my developer workstation, b) in the DAT environment and c) in the DQA environment. I'm not bothering with the PRD environment as it's essentially the same as DQA. (If you haven't been following along with this series please see this post for an explanation of the environments in my pipeline.) I also want to configure my web servers running IIS to send server telemetry to Azure.
Azure Portal Configuration
The starting point is some foundation work in Azure. We need to create three Application Insights resources inside three different resource groups representing the development workstation, the DAT environment and the DQA environment. A resource group for the development workstation doesn't exist so the first step is to create a new resource group called PRM-DEV. Then create three Application Insights resources in each of the resource groups -- I used the same names as the resource groups. For the DAT environment for example:

The final result should look something like this (note I added the resource group column in to the table):

Add the Application Insights SDK
With the Azure foundation work out of the way we can now turn our attention to adding the Application Insights SDK to the Contoso University ASP.NET application. (You can get the starting code from my GitHub repository here.) Application Insights is a NuGet package but it can be added by right-clicking the web project and choosing Add Application Insights Telemetry:

You are then presented with a configuration dialog which will allow you to select the correct Azure subscription and then the Application Insights resource -- in this case the one for the development environment:

You can then run Contoso University and see telemetry appear in both Visual Studio and the Azure portal. There is a wealth of information available so do explore the links to understand the extent.
Configure for Multiple Environments
As things stand we have essentially hard-coded Contoso University with an instrumentation key to send telemetry to just one Application Insights resource (PRM-DEV). Instrumentation keys are specific to one Application Insights resource so if we were to leave things as they are then a deployment of the application to the delivery pipeline would cause each environment to send its telemetry to the PRM-DEV Application Insights resource which would cause utter confusion. To fix this the following procedure can be used to amend an ASP.NET MVC application so that an instrumentation key can be passed in as a configuration variable as part of the deployment process:
- Add an iKey attribute to the appSettings section of Web.config (don't forget to use your own instrumentation key value from ApplicationInsights.config):
|
|
<appSettings> <!-- Other settings here --> <add key="iKey" value="8fc11978-dd5b-7b87-addc-965329534108"/> </appSettings> |
- Add a transform to Web.Release.config that consists of a token (__IKEY__) that can be used by Release Management:
|
|
<appSettings> <add key="iKey" value="__IKEY__" xdt:Transform="SetAttributes" xdt:Locator="Match(key)"/> </appSettings> |
- Add the following code to Application_Start in Global.asax.cs:
|
|
Microsoft.ApplicationInsights.Extensibility.TelemetryConfiguration.Active.InstrumentationKey = System.Web.Configuration.WebConfigurationManager.AppSettings["iKey"]; |
- As part of the Application Insights SDK installation Views.Shared._Layout.cshtml is altered with some JavaScript that adds the iKey to each page. This isn't dynamic and the JavaScript instrumentationKey line needs altering to make it dynamic as follows:
|
|
instrumentationKey: "@Microsoft.ApplicationInsights.Extensibility.TelemetryConfiguration.Active.InstrumentationKey" |
- Remove or comment out the InstrumentationKey section in ApplicationInsights.config.
As a final step run the application to ensure that Application Insights is still working. The code that accompanies this post can be downloaded from my GitHub account here.
Amend Release Management
As things stand a release build of Contoso University will have a tokenised appSettings key in Web.config as follows:
|
|
<add key="iKey" value="__IKEY__" /> |
When the build is deployed to the DAT and DQA environments the __IKEY__ token needs replacing with the instrumentation key for the respective resource group. This is achieved as follows:
- In the ContosoUniversity release definition click on the ellipsis of the DAT environment and choose Configure Variables. This will bring up a dialog to add an InstrumentationKey variable:

- The value for InstrumentationKey can be copied from the Azure portal. Navigate to Application Insights and then to the resource (PRM-DAT in the above screenshot) and then Configure > Properties where Instrumentation Key is to be found.
- The preceding process should be repeated for the DQA environment.
- Whilst still editing the release definition, edit the Website configuration tasks of both environments so that the Deployment > Scrip Arguments field takes a new parameter at the end called $(InstrumentationKey):

- In Visual Studio with the ContosoUniversity solution open, edit ContosoUniversity.Web.Deploy.Website.ps1 to accept the new InstrumentationKey as a parameter, add it to the $configurationData block and to use it in the ReplaceWebConfigTokens DSC configuration:
|
|
xTokenize ReplaceWebConfigTokens { Recurse = $false Tokens = @{DATA_SOURCE = $Node.SqlServerName; INITIAL_CATALOG = "ContosoUniversity"; IKEY = $Node.InstrumentationKey} UseTokenFiles = $false Path = "C:\temp\website" SearchPattern = "web.config" } |
- Check in the code changes so that a build and release are triggered and then check that the Application Insights resources in the Azure portal are displaying telemetry.
Install Release Annotations
A handy feature that became available in early 2016 was the ability to add Release Annotations, which is a way to identify releases in the Application Insights Metrics Explorer. Getting this set up is as follows:
- Release Annotations is an extension for VSTS or TFS 2015.2 and later and needs to be installed from the marketplace via this page. I installed it for my VSTS account.
- In the release definition, for each environment (I'm just showing the DAT environment below) add two variables -- ApplicationId and ApiKey but leave the window open for editing:

- In a separate browser window, navigate to the Application Insights resource for that environment in the Azure portal and then to the API Access section.
- Click on Create API key and complete the details as follows:

- Clicking Generate key will do just that:

- You should now copy the Application ID value hand API key value (both highlighted in the screenshot above) to the respective text boxes in the browser window where the release definition environment variables window should still be open. After marking the ApiKey as a secret with the padlock icon this window can now be closed.
- The final step is to add a Release Annotation task to the release definition:

- The Release Annotation is then edited with the ApplicationId and ApiKey variables:

- The net result of this can be seen in the Application Insights Metrics Explorer following a successful release where the release is displayed as a blue information icon:

- Clicking the icon opens the Release Properties window which displays rich details about the release.
Install the Application Insights Status Monitor
Since we are running our web application under IIS even more telemetry can be gleaned by installing the Application Insights Status Monitor:
- On the web servers running IIS download and install Status Monitor.
- Sign in to your Azure account in the configuration dialog.
- Use Configure settings to choose the correct Application Insights resource.
- Add the domain account the website is running under (via the application pool) to the Performance Monitor Users local security group.
The Status Monitor window should finish looking something like this:

See this documentation page to learn about the extra telemetry that will appear.
Wrapping Up
In this post I've only really covered configuring the basic components of Application Insights. In reality there's a wealth of other items to configure and the list is bound to grow. Here's a quick list I've come up with to give you a flavour:
This list however doesn't include the huge number of options for configuring Application Insights itself. There's enough to keep anyone interested in this sort of thing busy for weeks. The documentation is a great starting point -- check out the sidebar here.
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Automated Acceptance Tests with SpecFlow and Selenium Part 2
In part-one of this two-part mini series I covered how to get acceptance tests written using Selenium working as part of the deployment pipeline. In that post the focus was on configuring the moving parts needed to get some existing acceptance tests up-and-running with the new Release Management tooling in TFS or VSTS. In this post I make good on my promise to explain how to use SpecFlow and Selenium together to write business readable web tests as opposed to tests that probably only make sense to a developer.
If you haven't used SpecFlow before then I highly recommend taking the time to understand what it can do. The SpecFlow website has a good getting started guide here however the best tutorial I have found is Jason Roberts' Automated Business Readable Web Tests with Selenium and SpecFlow Pluralsight course. Pluralsight is a paid-for service of course but if you don't have a subscription then you might consider taking up the offer of the free trial just to watch Jason's course.
As I started to integrate SpecFlow in to my existing Contoso University sample application for this post I realised that the way I had originally written the Selenium-based page object model using a fluent API didn't work well with SpecFlow. Consequently I re-wrote the code to be more in line with the style used in Jason's Pluralsight course. The versions are on GitHub -- you can find the ‘before' code here and the ‘after' code here. The instructions that follow are written from the perspective of someone updating the ‘before' code version.
Install SpecFlow Components
To support SpecFlow development, components need to be installed at two levels. With the Contoso University sample application open in Visual Studio (actually not necessary for the first item):
- At the Visual Studio application level the SpecFlow for Visual Studio 2015 extension should be installed.
- At the Visual Studio solution level the ContosoUniversity.Web.AutoTests project needs to have the SpecFlow NuGet package installed.
You may also find if using MSTest that the specFlow section of App.config in ContosoUniversity.Web.AutoTests needs to have an <unitTestProvider name="MsTest" /> element added.
Update the Page Object Model
In order to see all the changes I made to update my page object model to a style that worked well with SpecFlow please examine the ‘after' code here. To illustrate the style of my updated model, I created CreateDepartmentPage class in ContosoUniversity.Web.SeFramework with the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
using System; using OpenQA.Selenium; using OpenQA.Selenium.Support.PageObjects; namespace ContosoUniversity.Web.SeFramework { public class CreateDepartmentPage { [FindsBy(How = How.Id, Using = "Name")] private IWebElement _name; [FindsBy(How = How.Id, Using = "Budget")] private IWebElement _budget; [FindsBy(How = How.Id, Using = "StartDate")] private IWebElement _startDate; [FindsBy(How = How.Id, Using = "InstructorID")] private IWebElement _administrator; [FindsBy(How = How.XPath, Using = "//input[@value='Create']")] private IWebElement _submit; public CreateDepartmentPage() { PageFactory.InitElements(Driver.Instance, this); } public static CreateDepartmentPage NavigateTo() { Driver.Instance.Navigate().GoToUrl("http://" + Driver.BaseAddress + "/Department/Create"); return new CreateDepartmentPage(); } public string Name { set { _name.SendKeys(value); } } public decimal Budget { set { _budget.SendKeys(value.ToString()); } } public DateTime StartDate { set { _startDate.SendKeys(value.ToString()); } } public string Administrator { set { _administrator.SendKeys(value); } } public DepartmentsPage Create() { _submit.Click(); return new DepartmentsPage(); } } } |
The key difference is that rather than being a fluent API the model now consists of separate properties that more easily map to SpecFlow statements.
Add a Basic SpecFlow Test
To illustrate some of the power of SpecFlow we'll first add a basic test and then make some improvements to it. The test should be added to ContosoUniversity.Web.AutoTests -- if you are using my ‘before' code you'll want to delete the existing C# class files that contain the tests written for the earlier page object model.
- Right-click ContosoUniversity.Web.AutoTests and choose Add > New Item. Select SpecFlow Feature File and call it Department.feature.
- Replace the template text in Department.feature with the following:
|
|
Feature: Department In order to expand Contoso University As an administrator I want to be able to create a new Department Scenario: New Department Created Successfully Given I am on the Create Department page And I enter a randomly generated Department name And I enter a budget of £1400 And I enter a start date of today And I enter an administrator with name of Kapoor When I submit the form Then I should see a new department with the specified name |
- Right-click Department.feature in the code editor and choose Generate Step Definitions which will generate the following dialog:

- By default this will create a DepartmentSteps.cs file that you should save in ContosoUniversity.Web.AutoTests.
- DepartmentSteps.cs now needs to be fleshed-out with code that refers back to the page object model. The complete class is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
using System; using TechTalk.SpecFlow; using ContosoUniversity.Web.SeFramework; using Microsoft.VisualStudio.TestTools.UnitTesting; namespace ContosoUniversity.Web.AutoTests { [Binding] public class DepartmentSteps { private CreateDepartmentPage _createDepartmentPage; private DepartmentsPage _departmentsPage; private string _departmentName; [Given(@"I am on the Create Department page")] public void GivenIAmOnTheCreateDepartmentPage() { _createDepartmentPage = CreateDepartmentPage.NavigateTo(); } [Given(@"I enter a randomly generated Department name")] public void GivenIEnterARandomlyGeneratedDepartmentName() { _departmentName = Guid.NewGuid().ToString(); _createDepartmentPage.Name = _departmentName; } [Given(@"I enter a budget of £(.*)")] public void GivenIEnterABudgetOf(int p0) { _createDepartmentPage.Budget = p0; } [Given(@"I enter a start date of today")] public void GivenIEnterAStartDateOfToday() { _createDepartmentPage.StartDate = DateTime.Today; } [Given(@"I enter an administrator with name of Kapoor")] public void GivenIEnterAnAdministratorWithNameOfKapoor() { _createDepartmentPage.Administrator = "Kapoor"; } [When(@"I submit the form")] public void WhenISubmitTheForm() { _departmentsPage = _createDepartmentPage.Create(); } [Then(@"I should see a new department with the specified name")] public void ThenIShouldSeeANewDepartmentWithTheSpecifiedName() { Assert.IsTrue(_departmentsPage.DoesDepartmentExistWithName(_departmentName)); } [BeforeScenario] public void Init() { Driver.Initialize(); } [AfterScenario] public void Cleanup() { Driver.Close(); } } } |
If you take a moment to examine the code you'll see the following features:
- The presence of methods with the BeforeScenario and AfterScenario attributes to initialise the test and clean up afterwards.
- Since we specified a value for Budget in Department.feature a method step with a (poorly named) parameter was created for reusability.
- Although we specified a name for the Administrator the step method wasn't parameterised.
As things stand though this test is complete and you should see a NewDepartmentCreatedSuccessfully test in Test Explorer which when run (don't forget IIS Express needs to be running) should turn green.
Refining the SpecFlow Test
We can make some improvements to DepartmentSteps.cs as follows:
- The GivenIEnterABudgetOf method can have its parameter renamed to budget.
- The GivenIEnterAnAdministratorWithNameOfKapoor method can be parameterised by changing as follows:
|
|
[Given(@"I enter an administrator with name of (.*)")] public void GivenIEnterAnAdministratorWithNameOf(string administrator) { _createDepartmentPage.Administrator = administrator; } |
In the preceding change note the change to both the attribute and the method name.
Updating the Build Definition
In order to start integrating SpecFlow tests in to the continuous delivery pipeline the first step is to update the build definition, specifically the AcceptanceTests artifact that was created in the previous post which needs amending to include TechTalk.SpecFlow.dll as a new item of the Contents property. A successful build should result in this dll appearing in the Artifacts Explorer window for the AcceptanceTests artifact:

Update the Test Plan with a new Test Case
If you are running your tests using the test assembly method then you should find that they just run without and further amendment. If on the other hand you are using the test plan method then you will need to remove the test cases based on the old Selenium tests and add a new test case (called New Department Created Successfully to match the scenario name) and edit it in Visual Studio to make it automated.
And Finally
Do be aware that I've only really scratched the surface in terms of what SpecFlow can do and there's plenty more functionality for you to explore. Whilst it's not really the subject of this post it's worth pointing out that when deciding to adopt acceptance tests as part of your continuous delivery pipeline it's worth doing so in a considered way. If you don't it's all too easy to wake up one day to realise you have hundreds of tests which take may hours to run and which require a significant amount of time to maintain. To this end do have a listen to Dave Farley's QCon talk on Acceptance Testing for Continuous Delivery.
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Automated Acceptance Tests with SpecFlow and Selenium Part 1
In the previous post in this series we covered using Release Management to deploy PowerShell DSC scripts to target nodes that both configured the nodes for web and database roles and then deployed our sample application. With this done we are now ready to do useful work with our deployment pipeline, and the big task for many teams is going to be running automated acceptance tests to check that previously developed functionality still works as expected as an application undergoes further changes.
I covered how to create a page object model framework for running Selenium web tests in my previous blog series on continuous delivery here. The good news is that nothing much has changed and the code still runs fine, so to learn about how to create a framework please refer to this post. However one thing I didn't cover in the previous series was how to use SpecFlow and Selenium together to write business readable web tests and that's something I'll address in this series. Specifically, in this post I'll cover getting acceptance tests working as part of the deployment pipeline and in the next post I'll show how to integrate SpecFlow.
What We're Hoping to Achieve
The acceptance tests are written using Selenium which is able to automate ‘driving' a web browser to navigate to pages, fill in forms, click on submit buttons and so on. Whilst these tests are created on and thus able to run on developer workstations the typical scenario is that the number of tests quickly mounts making it impractical to run them locally. In any case running them locally is of limited use since what we really want to know is if checked-in code changes from team members have broken any tests.
The solution is to run the tests in an environment that is part of the deployment pipeline. In this blog series I call that the DAT (development automated test) environment, which is the first stage of the pipeline after the build process. As I've explained previously in this blog series, the DAT environment should be configured in such a way as to minimise the possibility of tests failing due to factors other than code issues. I solve this for web applications by having the database, web site and test browser all running on the same node.
Make Sure the Tests Work Locally
Before attempting to get automated tests running in the deployment pipeline it's a good idea to confirm that the tests are running locally. The steps for doing this (in my case using Visual Studio 2015 Update 2 on a workstation with FireFox already installed) are as follows:
- If you don't already have a working Contoso University sample application available:
- Download the code that accompanies this post from my GitHub site here.
- Unblock and unzip the solution to a convenient location and then build it to restore NuGet packages.
- In ContosoUniversity.Database open ContosoUniversity.publish.xml and then click on Publish to create the ContosoUniversity database in LocalDB.
- Run ContosoUniversity.Web (and in so doing confirm that Contoso University is working) and then leaving the application running in the browser switch back to Visual Studio and from the Debug menu choose Detatch All. This leaves IIS Express running which FireFox needs to be able to navigate to any of the application's URLs.
- From the Test menu navigate to Playlist > Open Playlist File and open AutoWebTests.playlist which lives under ContosoUniversity.Web.AutoTests.
- In Test Explorer two tests (Can_Navigate_To_Departments and Can_Create_Department) should now appear and these can be run in the usual way. FireFox should open and run each test which will hopefully turn green.
Edit the Build to Create an Acceptance Tests Artifact
The first step to getting tests running as part of the deployment pipeline is to edit the build to create an artifact containing all the files needed to run the tests on a target node. This is achieved by editing the ContosoUniversity.Rel build definition and adding a Copy Publish Artifact task. This should be configured as follows:
- Copy Root = $(build.stagingDirectory)
- Contents =
- ContosoUniversity.Web.AutoTests.*
- ContosoUniversity.Web.SeFramework.*
- Microsoft.VisualStudio.QualityTools.UnitTestFramework.*
- WebDriver.*
- Artifact Name = AcceptanceTests
- Artifact Type = Server
After queuing a successful build the AcceptanceTests artifact should appear on the build's Artifacts tab:

Edit the Release to Deploy the AcceptanceTests Artifact
Next up is copying the AcceptanceTests artifact to a target node -- in my case a server called PRM-DAT-AIO. This is no different from the previous post where we copied database and website artifacts and is a case of adding a Windows Machine File Copy task to the DAT environment of the ContosoUniversity release and configuring it appropriately:

Deploy a Test Agent
The good news for those of us working in the VSTS and TFS 2015 worlds is that test controllers are a thing of the past because Agents for Microsoft Visual Studio 2015 handle communicating with VSTS or TFS 2015 directly. The agent needs to be deployed to the target node and this is handled by adding a Visual Studio Test Agent Deployment task to the DAT environment. The configuration of this task is very straightforward (see here) however you will probably want to create a dedicated domain service account for the agent service to run under. The process is slightly different between VSTS and TFS 2015 Update 2.1 in that in VSTS the machine details can be entered directly in the task whereas in TFS there is a requirement to create a Test Machine Group.
Running Tests -- Test Assembly Method
In order to actually run the acceptance tests we need to add a Run Functional Tests task to the DAT pipeline directly after the Visual Studio Test Agent Deployment task. Examining this task reveals two ways to select the tests to be run -- Test Assembly or Test Plan. Test Assembly is the most straightforward and needs very little configuration:
- Test Machine Group (TFS) or Machines (VSTS) = Group name or $(TargetNode-DAT-AIO)
- Test Drop Location = $(TargetNodeTempFolder)\AcceptanceTests
- Test Selection = Test Assembly
- Test Assembly = **\*test*.dll
- Test Run Title = Acceptance Tests
As you will see though there are many more options that can be configured -- see the help page here for details.
Before you create a build to test these setting out you will need to make sure that the node where the tests are to be run from is specified in Driver.cs which lives in ContosoUniversity.Web.SeFramework. You will also need to ensure that FireFox is installed on this node. I've been struggling to reliably automate the installation of FireFox which turned out to be just as well because I was trying to automate the installation of the latest version from the Mozilla site. This turns out to be a bad thing because the latest version at time of writing (47.0) doesn't work with the latest (at time of writing) version of Selenium (2.53.0). Automation installation efforts for FireFox therefore need to centre around installing a Selenium-compatible version which makes things easier since the installer can be pre-downloaded to a known location. I ran out of time and installed FireFox 46.1 (compatible with Selenium 2.53.0) manually but this is something I'll revisit. Disabling automatic updates in FireFox is also essential to ensure you don't get out of sync with Selenum.
When you finally get your tests running you can see the results form the web portal by navigating to Test > Runs. You should hopefully see something similar to this:

Running Tests -- Test Plan Method
The first question you might ask about the Test Plan method is why bother if the Test Assembly method works? Of course, if the Test Assembly method gives you what you need then feel free to stick with that. However you might need to use the Test Plan method if a test plan already exists and you want to continue using it. Another reason is the possibility of more flexibility in choosing which tests to run. For example, you might organise your tests in to logical areas using static suites and then use query-based suites to choose subsets of tests, perhaps with the use of tags.
To use the Test Plan method, in the web portal navigate to Test > Test Plan and then:
- Use the green cross to create a new test plan called Acceptance Tests.
- Use the down arrow next to Acceptance Tests to create a New static suite called Department:

- Within the Department suite use the green cross to create two new test cases called Can_Navigate_To_Departments and Can_Create_Department (no other configuration necessary):

- Making a note of the test case IDs, switch to Visual Studio and in Team Explorer > Work Items search for each test case in turn to open it for editing.
- For each test case, click on Associated Automation (screenshot below is VSTS and looks slightly different from TFS) and then click on the ellipsis to bring up the Choose Test dialogue where you can choose the correct test for the test case:

- With everything saved switch back to the web portal Release hub and edit the Run Functional Tests task as follows:
- Test Selection = Test Plan
- Test Plan = Acceptance Tests
- Test Suite =Acceptance Tests\Department
With the configuration complete trigger a new release and if everything has worked you should be able to navigate to Test > Runs and see output similar to the Test Assembly method.
That's it for now. In the next post in this series I'll look at adding SpecFlow in to the mix to make the acceptance tests business readable.
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Server Configuration and Application Deployment with Release Management
At this point in my blog series on Continuous Delivery with TFS / VSTS we have finally reached the stage where we are ready to start using the new web-based release management capabilities of VSTS and TFS. The functionality has been in VSTS for a little while now but only came to TFS with Update 2 of TFS 2015 which was released at the end of March 2016.
Don't tell my wife but I'm having a torrid love affair with the new TFS / VSTS Release Management. It's flippin' brilliant! Compared to the previous WPF desktop client it's a breath of fresh air: easy to understand, quick to set up and a joy to use. Sure there are some improvements that could be made (and these will come in time) but for the moment, for a relatively new product, I'm finding the experience extremely agreeable. So let's crack on!
Setting the Scene
The previous posts in this series set the scene for this post but I'll briefly summarise here. We'll be deploying the Contoso University sample application which consists of an ASP.NET MVC website and a SQL Server database which I've converted to a SQL Server Database Project so deployment is by DACPAC. We'll be deploying to three environments (DAT, DQA and PRD) as I explain here and not only will we be deploying the application we'll first be making sure the environments are correctly configured with PowerShell DSC using an adaptation of the procedure I describe here.
My demo environment in Azure is configured as a Windows domain and includes an instance of TFS 2015 Update 2 which I'll be using for this post as it's the lowest common denominator, although I will point out any VSTS specifics where needed. We'll be deploying to newly minted Windows Server 2012 R2 VMs which have been joined to the domain, configured with WMF 5.0 and had their domain firewall turned off -- see here for details. (Note that if you are using versions of Windows server earlier than 2012 that don't have remote management turned on you have a bit of extra work to do.) My TFS instance is hosting the build agent and as such the agent can ‘see' all the machines in the domain. I'm using Integrated Security to allow the website to talk to the database and use three different domain accounts (CU-DAT, CU-DQA and CU-PRD) to illustrate passing different credentials to different environments. I assume you have these set up in advance.
As far as development tools are concerned I'm using Visual Studio 2015 Update 2 with PowerShell Tools installed and Git for version control within a TFS / VSTS team project. It goes without saying that for each release I'm building the application only once and as part of the build any environment-specific configuration is replaced with tokens. These tokens are replaced with the correct values for that environment as that same tokenised build moves through the deployment pipeline.
Writing Server Configuration Code Alongside Application Code
A key concept I am promoting in this blog post series is that configuring the servers that your application will run on should not be an afterthought and neither should it be a manual click-through-GUI process. Rather, you should be configuring your servers through code and that code should be written at the same time as you write your application code. Furthermore the server configuration code should live with your application code. To start then we need to configure Contoso University for this way of working. If you are following along you can get the starting point code from here.
- Open the ContosoUniversity solution in Visual Studio and add new folders called Deploy to the ContosoUniversity.Database and ContosoUniversity.Web projects.
- In ContosoUniversity.Database\Deploy create two new files: Database.ps1 and DbDscResources.ps1. (Note that SQL Server Database Projects are a bit fussy about what can be created in Visual Studio so you might need to create these files in Windows Explorer and add them in as new items.)
- Database.ps1 should contain the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
[CmdletBinding()] param( [Parameter(Position=1)] [string]$domainSqlServerSetupLogin, [Parameter(Position=2)] [string]$domainSqlServerSetupPassword, [Parameter(Position=3)] [string]$sqlServerSaPassword, [Parameter(Position=4)] [string]$domainUserForIntegratedSecurityLogin ) <# Password parameters included intentionally to check for environment cloning errors where failure to explicitly set the password in a cloned environment causes an off-by-one error which these outputs can help track down #> Write-Verbose "The value of parameter `$domainSqlServerSetupLogin is $domainSqlServerSetupLogin" -Verbose Write-Verbose "The value of parameter `$domainSqlServerSetupPassword is $domainSqlServerSetupPassword" -Verbose Write-Verbose "The value of parameter `$sqlServerSaPassword is $sqlServerSaPassword" -Verbose Write-Verbose "The value of parameter `$domainUserForIntegratedSecurityLogin is $domainUserForIntegratedSecurityLogin" -Verbose $domainSqlServerSetupCredential = New-Object System.Management.Automation.PSCredential ($domainSqlServerSetupLogin, (ConvertTo-SecureString -String $domainSqlServerSetupPassword -AsPlainText -Force)) $sqlServerSaCredential = New-Object System.Management.Automation.PSCredential ("sa", (ConvertTo-SecureString -String $sqlServerSaPassword -AsPlainText -Force)) $configurationData = @{ AllNodes = @( @{ NodeName = $env:COMPUTERNAME PSDscAllowDomainUser = $true PSDscAllowPlainTextPassword = $true DomainSqlServerSetupCredential = $domainSqlServerSetupCredential SqlServerSaCredential = $sqlServerSaCredential DomainUserForIntegratedSecurityLogin = $domainUserForIntegratedSecurityLogin } ) } Configuration Database { Import-DscResource –ModuleName PSDesiredStateConfiguration Import-DscResource -ModuleName @{ModuleName="xSQLServer";ModuleVersion="1.5.0.0"} Import-DscResource -ModuleName @{ModuleName="xDatabase";ModuleVersion="1.4.0.0"} Import-DscResource -ModuleName @{ModuleName="xReleaseManagement";ModuleVersion="1.0.0.0"} Node $AllNodes.NodeName { WindowsFeature "NETFrameworkCore" { Ensure = "Present" Name = "NET-Framework-Core" } xSqlServerSetup "SQLServerEngine" { DependsOn = "[WindowsFeature]NETFrameworkCore" SourcePath = "\\prm-core-dc\DscInstallationMedia" SourceFolder = "SqlServer2014" SetupCredential = $Node.DomainSqlServerSetupCredential InstanceName = "MSSQLSERVER" Features = "SQLENGINE" SecurityMode = "SQL" SAPwd = $Node.SqlServerSaCredential } xDatabase DeployDac { DependsOn = "[xSqlServerSetup]SQLServerEngine" Ensure = "Present" SqlServer = $Node.Nodename SqlServerVersion = "2014" DatabaseName = "ContosoUniversity" Credentials = $Node.SqlServerSaCredential DacPacPath = "C:\temp\Database\ContosoUniversity.Database.dacpac" DacPacApplicationName = "ContosoUniversity.Database" } xTokenize ReplacePermissionsScriptConfigTokens { DependsOn = "[xDatabase]DeployDac" recurse = $false tokens = @{LOGIN_OR_USER = $Node.DomainUserForIntegratedSecurityLogin; DB_NAME = "ContosoUniversity"} useTokenFiles = $false path = "C:\temp\Database\Deploy" searchPattern = "*.sql" } Script ApplyPermissions { DependsOn = "[xTokenize]ReplacePermissionsScriptConfigTokens" SetScript = { $cmd= "& 'C:\Program Files\Microsoft SQL Server\Client SDK\ODBC\110\Tools\Binn\sqlcmd.exe' -S localhost -i 'C:\temp\Database\Deploy\Create login and database user.sql' " Invoke-Expression $cmd } TestScript = { $false } GetScript = { @{ Result = "" } } } # Configure for debugging / development mode only #xSqlServerSetup "SQLServerManagementTools" #{ # DependsOn = "[WindowsFeature]NETFrameworkCore" # SourcePath = "\\prm-core-dc\DscInstallationMedia" # SourceFolder = "SqlServer2014" # SetupCredential = $Node.DomainSqlServerSetupCredential # InstanceName = "NULL" # Features = "SSMS,ADV_SSMS" #} } } Database -ConfigurationData $configurationData |
- DbDscResources.ps1 should contain the following code:
|
|
$customModulesDestination = Join-Path $env:SystemDrive "\Program Files\WindowsPowerShell\Modules" # Modules need to have been copied to this UNC from a machine where they were installed $customModulesSource = "\\prm-core-dc\DscResources" Copy-Item -Verbose -Force -Recurse -Path (Join-Path $customModulesSource xSqlServer) -Destination $customModulesDestination Copy-Item -Verbose -Force -Recurse -Path (Join-Path $customModulesSource xDatabase) -Destination $customModulesDestination Copy-Item -Verbose -Force -Recurse -Path (Join-Path $customModulesSource xReleaseManagement) -Destination $customModulesDestination |
- In ContosoUniversity.Web\Deploy create two new files: Website.ps1 and WebDscResources.ps1.
- Website.ps1 should contain the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 |
[CmdletBinding()] param( [Parameter(Position=1)] [string]$domainUserForIntegratedSecurityLogin , [Parameter(Position=2)] [string]$domainUserForIntegratedSecurityPassword, [Parameter(Position=3)] [string]$sqlServerName ) <# Password parameters included intentionally to check for environment cloning errors where failure to explicitly set the password in a cloned environment causes an off-by-one error which these outputs can help track down #> Write-Verbose "The value of parameter `$domainUserForIntegratedSecurityLogin is $domainUserForIntegratedSecurityLogin" -Verbose Write-Verbose "The value of parameter `$domainUserForIntegratedSecurityPassword is $domainUserForIntegratedSecurityPassword" -Verbose Write-Verbose "The value of parameter `$sqlServerName is $sqlServerName" -Verbose $domainUserForIntegratedSecurityCredential = New-Object System.Management.Automation.PSCredential ($domainUserForIntegratedSecurityLogin, (ConvertTo-SecureString -String $domainUserForIntegratedSecurityPassword -AsPlainText -Force)) $configurationData = @{ AllNodes = @( @{ NodeName = $env:COMPUTERNAME DomainUserForIntegratedSecurityLogin = $domainUserForIntegratedSecurityLogin DomainUserForIntegratedSecurityCredential = $domainUserForIntegratedSecurityCredential SqlServerName = $sqlServerName PSDscAllowDomainUser = $true PSDscAllowPlainTextPassword = $true } ) } Configuration Web { Import-DscResource –ModuleName PSDesiredStateConfiguration Import-DscResource –ModuleName @{ModuleName="cWebAdministration";ModuleVersion="2.0.1"} Import-DscResource -ModuleName @{ModuleName="xWebAdministration";ModuleVersion="1.10.0.0"} Import-DscResource -ModuleName @{ModuleName="xReleaseManagement";ModuleVersion="1.0.0.0"} Node $AllNodes.NodeName { # Configure for web server role WindowsFeature DotNet45Core { Ensure = 'Present' Name = 'NET-Framework-45-Core' } WindowsFeature IIS { Ensure = 'Present' Name = 'Web-Server' } WindowsFeature AspNet45 { Ensure = "Present" Name = "Web-Asp-Net45" } # Only turn off whilst sorting out the web files - needs to be on for rest of script to work Script StopIIS { DependsOn = "[WindowsFeature]IIS" SetScript = { Stop-Service W3SVC } TestScript = { $false } GetScript = { @{ Result = "" } } } # Make sure the web folder has the latest website files xTokenize ReplaceWebConfigTokens { Recurse = $false Tokens = @{DATA_SOURCE = $Node.SqlServerName; INITIAL_CATALOG = "ContosoUniversity"} UseTokenFiles = $false Path = "C:\temp\website" SearchPattern = "web.config" } Script DeleteExisitngWebsiteFilesSoAbsolutelyCertainAllFilesComeFromTheBuild { DependsOn = "[xTokenize]ReplaceWebConfigTokens" SetScript = { Remove-Item "C:\inetpub\ContosoUniversity" -Force -Recurse -ErrorAction SilentlyContinue } TestScript = { $false } GetScript = { @{ Result = "" } } } File CopyWebsiteFiles { DependsOn = "[Script]DeleteExisitngWebsiteFilesSoAbsolutelyCertainAllFilesComeFromTheBuild" Ensure = "Present" Force = $true Recurse = $true Type = "Directory" SourcePath = "C:\temp\website" DestinationPath = "C:\inetpub\ContosoUniversity" } File RemoveDeployFolder { DependsOn = "[File]CopyWebsiteFiles" Ensure = "Absent" Force = $true Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity\Deploy" } Script StartIIS { DependsOn = "[File]RemoveDeployFolder" SetScript = { Start-Service W3SVC } TestScript = { $false } GetScript = { @{ Result = "" } } } # Configure custom app pool xWebAppPool ContosoUniversity { DependsOn = "[WindowsFeature]IIS" Ensure = "Present" Name = "ContosoUniversity" State = "Started" } cAppPool ContosoUniversity { DependsOn = "[xWebAppPool]ContosoUniversity" Name = "ContosoUniversity" IdentityType = "SpecificUser" UserName = $Node.DomainUserForIntegratedSecurityLogin Password = $Node.DomainUserForIntegratedSecurityCredential } # Advanced configuration xWebsite ContosoUniversity { DependsOn = "[cAppPool]ContosoUniversity" Ensure = "Present" Name = "ContosoUniversity" State = "Started" PhysicalPath = "C:\inetpub\ContosoUniversity" BindingInfo = MSFT_xWebBindingInformation { Protocol = 'http' Port = '80' HostName = $Node.NodeName IPAddress = '*' } ApplicationPool = "ContosoUniversity" } # Clean up the uneeded website and application pools xWebsite Default { Ensure = "Absent" Name = "Default Web Site" } xWebAppPool NETv45 { Ensure = "Absent" Name = ".NET v4.5" } xWebAppPool NETv45Classic { Ensure = "Absent" Name = ".NET v4.5 Classic" } xWebAppPool Default { Ensure = "Absent" Name = "DefaultAppPool" } File wwwroot { Ensure = "Absent" Type = "Directory" DestinationPath = "C:\inetpub\wwwroot" Force = $True } # Configure for debugging / development mode only #WindowsFeature IISTools #{ # Ensure = "Present" # Name = "Web-Mgmt-Tools" #} } } Web -ConfigurationData $configurationData |
- WebDscResources.ps1 should contain the following code:
|
|
$customModulesDestination = Join-Path $env:SystemDrive "\Program Files\WindowsPowerShell\Modules" # Modules need to have been copied to this UNC from a machine where they were installed $customModulesSource = "\\prm-core-dc\DscResources" Copy-Item -Verbose -Force -Recurse -Path (Join-Path $customModulesSource xWebAdministration) -Destination $customModulesDestination Copy-Item -Verbose -Force -Recurse -Path (Join-Path $customModulesSource cWebAdministration) -Destination $customModulesDestination Copy-Item -Verbose -Force -Recurse -Path (Join-Path $customModulesSource xReleaseManagement) -Destination $customModulesDestination |
- In ContosoUniversity.Database\Scripts move Create login and database user.sql to the Deploy folder and remove the Scripts folder.
- Make sure all these files have their Copy to Output Directory property set to Copy always. For the files in ContosoUniversity.Database\Deploy the Build Action property should be set to None.
The Database.ps1 and Website.ps1 scripts contain the PowerShell DSC to both configure servers for either IIS or SQL Server and then to deploy the actual component. See my Server Configuration as Code with PowerShell DSC post for more details. (At the risk of jumping ahead to the deployment part of this post, the bits to be deployed are copied to temp folders on the target nodes -- hence references in the scripts to C:\temp\$whatever$.)
In the case of the database component I'm using the xDatabase custom DSC resource to deploy the DACPAC. I came across a problem with this resource where it wouldn't install the DACPAC using domain credentials, despite the credentials having the correct permissions in SQL Server. I ended up having to install SQL Server using Mixed Mode authentication and installing the DACPAC using the sa login. I know, I know!
My preferred technique for deploying website files is plain xcopy. For me the requirement is to clear the old files down and replace them with the new ones. After some experimentation I ended up with code to stop IIS, remove the web folder, copy the new web folder from its temp location and then restart IIS.
Both the database and website have files with configuration tokens that needed replacing as part of the deployment. I'm using the xReleaseManagement custom DSC resource which takes a hash table of tokens (in the __TOKEN_NAME__ format) to replace.
In order to use custom resources on target nodes the custom resources need to be in place before attempting to run a configuration. I had hoped to use a push server technique for this but it was not to be since for this post at least I'm running the DSC configurations on the actual target nodes and the push server technique only works if the MOF files are created on a staging machine that has the custom resources installed. Instead I'm copying the custom resources to the target nodes just prior to running the DSC configurations and this is the purpose of the DbDscResources.ps1 and WebDscResources.ps1 files. The custom resources live on a UNC that is available to target nodes and get there by simply copying them from a machine where they have been installed (C:\Program Files\WindowsPowerShell\Modules is the location) to the UNC.
Create a Release Build
With the Visual Studio now configured (don't forget to commit the changes) we now need to create a build to check that initial code quality checks have passed and if so to publish the database and website components ready for deployment. Create a new build definition called ContosoUniversity.Rel and follow this post to configure the basics and this post to create a task to run unit tests. Note that for the Visual Studio Build task the MSBuild Arguments setting is /p:OutDir=$(build.stagingDirectory) /p:UseWPP_CopyWebApplication=True /p:PipelineDependsOnBuild=False /p:RunCodeAnalysis=True. This gives us a _PublishedWebsites\ContosoUniversity.Web folder (that contains all the web files that need to be deployed) and also runs the transformation to tokensise Web.config. Additionally, since we are outputting to $(build.stagingDirectory) the Test Assembly setting of the Visual Studio Test task needs to be $(build.stagingDirectory)\**\*UnitTests*.dll;-:**\obj\**. At some point we'll want to version our assemblies but I'll return to that in a another post.
One important step that has changed since my earlier posts is that the Restore NuGet Packages option in the Visual Studio Build task has been deprecated. The new way of doing this is to add a NuGet Installer task as the very first item and then in the Visual Studio Build task (in the Advanced section in VSTS) uncheck Restore NuGet Packages.
To publish the database and website as components -- or Artifacts (I'm using the TFS spelling) as they are known -- we use the Copy and Publish Build Artifacts tasks. The database task should be configured as follows:
- Copy Root = $(build.stagingDirectory)
- Contents =
- ContosoUniversity.Database.d*
- Deploy\Database.ps1
- Deploy\DbDscResources.ps1
- Deploy\Create login and database user.sql
- Artifact Name = Database
- Artifact Type = Server
Note that the Contents setting can take multiple entries on separate lines and we use this to be explicit about what the database artifact should contain. The website task should be configured as follows:
- Copy Root = $(build.stagingDirectory)\_PublishedWebsites
- Contents = **\*
- Artifact Name = Website
- Artifact Type = Server
Because we are specifying a published folder of website files that already has the Deploy folder present there's no need to be explicit about our requirements. With all this done the build should look similar to this:

In order to test the successful creation of the artifacts, queue a build and then -- assuming the build was successful -- navigate to the build and click on the Artifacts link. You should see the Database and Website artifact folders and you can examine the contents using the Explore link:

Create a Basic Release
With the artifacts created we can now turn our attention to creating a basic release to get them copied on to a target node and then perform a deployment. Switch to the Release hub in the web portal and use the green cross icon to create a new release definition. The Deployment Templates window is presented and you should choose to start with an Empty template. There are four immediate actions to complete:
- Provide a Definition name -- ContosoUniversity for example.
- Change the name of the environment that has been added to DAT.

- Click on Link to a build definition to link the release to the ContosoUniversity.Rel build definition.

- Save the definition.
Next up we need to add two Windows Machine File Copy tasks to copy each artifact to one node called PRM-DAT-AIO. (As a reminder the DAT environment as I define it is just one server which hosts both the website and the database and where automated testing takes place.) Although it's possible to use just one task here the result of selecting artifacts differs according to the selected node in the artifact tree. At the node root, folders are created for each artifact but go one node lower and they aren't. I want a procedure that works for all environments which is as follows:
- Click on Add tasks to bring up the Add Tasks window. Use the Deploy link to filter the list of tasks and Add two Windows Machine File Copy tasks:

- Configure the properties of the tasks as follows:
- Edit the names (use the pencil icon) to read Copy Database files and Copy Website files respectively.
- Source = $(System.DefaultWorkingDirectory)/ContosoUniversity.Rel/Database or $(System.DefaultWorkingDirectory)/ContosoUniversity.Rel/Website accordingly (use the ellipsis to select)
- Machines = PRM-DAT-AIO.prm.local
- Admin login = Supply a domain account login that has admin privileges for PRM-DAT-AIO.prm.local
- Password = Password for the above domain account
- Destination folder = C:\temp\Database or C:\temp\Website accordingly
- Advanced Options > Clean Target = checked
- Click the ellipsis in the DAT environment and choose Deployment conditions.

- Change the Trigger to After release creation and click OK to accept.
- Save the changes and trigger a release using the green cross next to Release. You'll be prompted to select a build as part of the process:

- If the release succeeds a C:\temp folder containing the artifact folders will have been created on on PRM-DAT-AIO.
- If the release fails switch to the Logs tab to troubleshoot. Permissions and whether the firewall has been configured to allow WinRM are the likely culprits. To preserve my sanity I do everything as domain admin and I have the domain firewall turned off. The usual warnings about these not necessarily being best practices in non-test environments apply!
Whilst you are checking the C:\temp folder on the target node have a look inside the artifact folders. They should both contain a Deploy folder that contains the PowerShell scripts that will be executed remotely using the PowerShell on Target Machines task. You'll need to configure two of each for the two artifacts as follows:
- Add two PowerShell on Target Machines tasks to alternately follow the Windows Machine File Copy tasks.
- Edit the names (use the pencil icon) to read Configure Database and Configure Website respectively.
- Configure the properties of the task as follows:
- Machines = PRM-DAT-AIO.prm.local
- Admin login = Supply a domain account that has admin privileges for PRM-DAT-AIO.prm.local
- Password = Password for the above domain account
- Protocol = HTTP
- Deployment > PowerShell Script = C:\temp\Database\Deploy\Database.ps1 or C:\temp\Website\Deploy\Website.ps1 accordingly
- Deployment > Initialization Script = C:\temp\Database\Deploy\DbDscResources.ps1 or C:\temp\Website\Deploy\WebDscResources.ps1 accordingly
- With reference to the parameters required by C:\temp\Database\Deploy\Database.ps1 configure Deployment > Script Arguments for the Database task as follows:
- $domainSqlServerSetupLogin = Supply a domain login that has privileges to install SQL Server on PRM-DAT-AIO.prm.local
- $domainSqlServerSetupPassword = Password for the above domain login
- $sqlServerSaPassword = Password you want to use for the SQL Server sa account
- $domainUserForIntegratedSecurityLogin = Supply a domain login to use for integrated security (PRM\CU-DAT in my case for the DAT environment)
- The finished result will be similar to: ‘PRM\Graham' ‘YourSecurePassword' ‘YourSecurePassword' ‘PRM\CU-DAT'
- With reference to the parameters required by C:\temp\Website\Deploy\Website.ps1 configure Deployment > Script Arguments for the Website task as follows:
- $domainUserForIntegratedSecurityLogin = Supply a domain login to use for integrated security (PRM\CU-DAT in my case for the DAT environment)
- $domainUserForIntegratedSecurityPassword = Password for the above domain account
- $sqlServerName = machine name for the SQL Server instance (PRM-DAT-AIO in my case for the DAT environment)
- The finished result will be similar to: ‘PRM\CU-DAT' ‘YourSecurePassword' ‘PRM-DAT-AIO'
At this point you should be able to save everything and the release should look similar to this:

Go ahead and trigger a new release. This should result in the PowerShell scripts being executed on the target node and IIS and SQL Server being installed, as well as the Contoso University application. You should be able to browse the application at http://prm-dat-aio. Result!
Variable Quality
Although we now have a working release for the DAT environment it will hopefully be obvious that there are serious shortcomings with the way we've configured the release. Passwords in plain view is one issue and repeated values is another. The latter issue is doubly of concern when we start creating further environments.
The answer to this problem is to create custom variables at both a ‘release' level and and at the ‘environment' level. Pretty much every text box seems to take a variable so you can really go to town here. It's also possible to create compound values based on multiple variables -- I used this to separate the location of the C:\temp folder from the rest of the script location details. It's worth having a bit of a think about your variable names in advance of using them because if you change your mind you'll need to edit every place they were used. In particular, if you edit the declaration of secret variables you will need to click the padlock to clear the value and re-enter it. This tripped me up until I added Write-Verbose statements to output the parameters in my DSC scripts and realised that passwords were not being passed through (they are asterisked so there is no security concern). (You do get the scriptArguments as output to the console but I find having them each on a separate line easier.)
Release-level variables are created in the Configuration section and if they are passwords can be secured as secrets by clicking the padlock icon. The release-level variables I created are as follows:

Environment-level variables are created by clicking the ellipsis in the environment and choosing Configure Variables. I created the following:

The variables can then be used to reconfigure the release as per this screen shot which shows the PowerShell on Target Machines Configure Database task:

The other tasks are obviously configured in a similar way, and notice how some fields use more than one variable. Nothing has a actually changed by replacing hard-coded values with variables so triggering another release should be successful.
Environments Matter
With a successful deployment to the DAT environment we can now turn our attention to the other stages of the deployment pipeline -- DQA and PRD. The good news here is that all the work we did for DAT can be easily cloned for DQA which can then be cloned for PRD. Here's the procedure for DQA which don't forget is a two-node deployment:
- In the Configuration section create two new release level variables:
- TargetNode-DQA-SQL = PRM-DQA-SQL.prm.local
- TargetNode-DQA-IIS = PRM-DQA-IIS.prm.local
- In the DAT environment click on the ellipsis and select Clone environment and name it DQA.
- Change the two database tasks so the Machines property is $(TargetNode-DQA-SQL).
- Change the two website tasks so the Machines property is $(TargetNode-DQA-IIS).
- In the DQA environment click on the ellipsis and select Configure variables and make the following edits:
- Change DomainUserForIntegratedSecurityLogin to PRM\CU-DQA
- Click on the padlock icon for the DomainUserForIntegratedSecurityPassword variable to clear it then re-enter the password and click the padlock icon again to make it a secret. Don't miss this!
- Change SqlServerName to PRM-DQA-SQL
- In the DQA environment click on the ellipsis and select Deployment conditions and set Trigger to No automated deployment.
With everything saved and assuming the PRM-DQA-SQL and PRM-DQA-SQL nodes are running the release can now be triggered. Assuming the deployment to DAT was successful the release will wait for DQA to be manually deployed (almost certainly what is required as manual testing could be going on here):

To keep things simple I didn't assign any approvals for this release (ie they were all automatic) but do bear in mind there is some rich and flexible functionality available around this. If all is well you should be able to browse Contoso University on http://prm-dqa-iis. I won't describe cloning DQA to create PRD as it's very similar to the process above. Just don't forget to re-enter cloned password values! Do note that in the Environment Variables view of the Configuration section you can view and edit (but not create) the environment-level variables for all environments:

This is a great way to check that variables are the correct values for the different environments.
And Finally...
There's plenty more functionality in Release Management that I haven't described but that's as far as I'm going in this post. One message I do want to get across is that the procedure I describe in this post is not meant to be a statement on the definitive way of using Release Management. Rather, it's designed to show what's possible and to get you thinking about your own situation and some of the factors that you might need to consider. As just one example, if you only have one application then the Visual Studio solution for the application is probably fine for the DSC code that installs IIS and SQL Server. However if you have multiple similar applications then almost certainly you don't want all that code repeated in every solution. Moving this code to the point at which the nodes are created could be an option here -- or perhaps there is a better way!
That's it for the moment but rest assured there's lots more to be covered in this series. If you want the final code that accompanies this post I've created a release here on my GitHub site.
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Server Configuration as Code with PowerShell DSC
I suspect I'm on reasonably safe ground when I venture to suggest that most software engineers developing applications for Windows servers (and the organisations they work for) have yet to make the leap from just writing the application code to writing both the application code and the code that will configure the servers the application will run on. Why do I suggest this? It's partly from experience in that I've never come across anyone developing for the Windows platform who is doing this (or at least they haven't mentioned it to me) and partly because up until fairly recently Microsoft haven't provided any tooling for implementing configuration as code (as this engineering practice is sometimes referred to). There are products from other vendors of course but they tend to have their roots in the Linux world and use languages such as Ruby (or DSLs based on Ruby) which is probably going to seriously muddy the waters for organisations trying to get everyone up to speed with PowerShell.
This has all changed relatively recently with the introduction of PowerShell DSC, Microsoft's solution for implementing configuration as code on Windows (and other platforms as it happens). With PowerShell DSC (and related technologies) the configuration of servers is expressed as programming code that can be versioned in source control. When a change is required to a server the code is updated and the new configuration is then applied to the server. This process is usually idempotent, ie the configuration can be applied repeatedly and will always give the same result. It also won't generate errors if the configuration is already in the desired state. Through version control we can audit how a configuration changes over time and being code it can be applied as required to ensure server roles in different environments, or multiple instances of the same server role in the same environment, have a consistent configuration.
So ostensibly Windows server developers now have no excuse not to start implementing configuration as code. But if we've managed so far without this engineering practice why all the fuss now? What benefit is it going to bring to the table? The key benefit is that it's a cure for that age-old problem of servers that might start life from a build script, but over the months (and possibly years) different technicians make necessary tweaks here and there until one day the server becomes a unique work of art that nobody could ever hope to reproduce. Server backups become critical and everyone dreads the day that the server will need to be upgraded or replaced.
If your application is very simple you might just get away with this state of affairs -- not that it makes it right or a best practice. However if your application is constantly evolving with concomitant configuration changes and / or you are going down the microservices route then you absolutely can't afford to hand-crank the configuration of your servers. Not only is the manual approach very error prone it's also hugely time-consuming, and has no place in a world of continuous delivery where shortening lead times and increasing reliability and repeatability is the name of the game.
So if there's no longer an excuse to implement configuration as code on the Windows platform why isn't there a mad rush to adopt it? In my view, for most mid-size IT departments working with existing budgets and staffing levels and an existing landscape of hand-cranked servers it's going to be a real slog to switch the configuration of a live estate to being managed by code. Once you start thinking about the complexities of analysing exiting servers (some of which might have been around for years and which might have all sorts of bespoke applications running on them) combined with devising a system of managing scores or even hundreds of servers it's clear that a task of this nature is almost certainly going to require a dedicated team. And despite the potential benefits that configuration as code promises most mid-size IT departments are likely to struggle to stand-up such a team.
So if it's going to be hard how does an organisation get started with configuration as code and PowerShell DSC? Although I don't have anywhere near all of the answers it is already clear to me that if your organisation is in the business of writing applications for Windows servers then you need to approach the problem from both ends of the server spectrum. At the far end of the spectrum is the live estate where server ‘drift' needs to be controlled using PowerShell DSC's ‘pull' mode. This is where servers periodically reach out to a central repository to pull their ‘true' configuration and make any adjustments accordingly. At the near end of the spectrum are the servers that form the continuous delivery pipeline which need to have configuration changes applied to them just before a new version of the application gets deployed to them. Happily PowerShell has a ‘push' mode which will work nicely for this purpose. There is also the live deployment situation. Here, live servers will need to have configuration changes pushed to them before application deployment takes place and then will need to switch over to pull mode to keep them true.
The way I see things at the moment is that PowerShell DSC pull mode is going to be hard to implement at scale because of the lack of tooling to manage it. Whilst you could probably manage a handful of servers in pull mode using PowerShell DSC script files, any more than a handful is going to cause serious pain without some kind of management framework such as the one that is available for Chef. The good news though is that getting started with PowerShell DSC push mode for configuring servers that comprise the deployment pipeline as part of application development activities is a much more realistic prospect.
Big Picture Time
I'm not going to be able to cover everything about making PowerShell DSC push mode work in one blog post so it's probably worth a few words about the bigger picture. One key concept to establish early on is that the code that will configure the server(s) that an application will reside on has to live and change alongside the application code. At the very least the server configuration code needs to be in the same version control branch as the application code and frequently it will make sense for it to be part of the same Visual Studio solution. I won't be presenting that approach in this blog post and instead will concentrate on the mechanics of getting PowerShell DSC push mode working and writing the configuration code that enables the Contoso University sample application (which requires IIS and SQL Server) to run. In a future post I'll have the code in the same Visual Studio solution as the Contoso University sample application and will explain how to build an artefact that is then deployed by the release management tooling in TFS / VSTS prior to deploying the application.
For anyone who has come across this post by chance it is part of my ongoing series about Continuous Delivery with TFS / VSTS, and you may find it helpful to refer to some of the previous posts to understand the full context of what I'm trying to achieve. I should also mention that this post isn't intended to be a PowerShell DSC tutorial and if you are new to the technology I have a Getting Started post here with a link collection of useful learning resources. With all that out of the way let's get going!
Getting Started
Taking the Infrastructure solution from this blog post as a starting point (available as a code release at my Infrastructure repo on GitHub, final version of this post's code here) add a new PowerShell Script Project called ConfigurationScripts. To this new project add a new PowerShell Script file called ContosoUniversity.ps1 and add a hash table and empty Configuration block called WebAndDatabase as follows:
|
|
$configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') } ) } Configuration WebAndDatabase { } |
We're going to need an environment to deploy in to so using the techniques described in previous posts (here and here) create a PRM-DAT-AIO server that is joined to the domain. This server will need to have Windows Management Framework 5.0 installed -- a manual process as far as this particular post is concerned but something that is likely to need automating in the future.
To test a basic working configuration we'll create a folder on PRM-DAT-AIO to act as the IIS physical path to the ContosoUniversity web files. Add the following lines of code to the beginning of the configuration block:
|
|
Import-DscResource –ModuleName PSDesiredStateConfiguration Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { File WebSiteFolder { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } } |
To complete the skeleton code add the following lines of code to the end of ContosoUniversity.ps1:
|
|
WebAndDatabase -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose Start-DSCConfiguration -Path C:\Dsc\Mof -Wait -Verbose -Force |
The code contained in ContosoUniversity.ps1 should now be as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
$configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') } ) } Configuration WebAndDatabase { Import-DscResource –ModuleName PSDesiredStateConfiguration Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { File WebSiteFolder { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } } } WebAndDatabase -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose Start-DSCConfiguration -Path C:\Dsc\Mof -Wait -Verbose -Force |
Although you can create this code from any developer workstation you need to ensure that you can run it from a workstation that is joined to the same domain as PRM-DAT-AIO and has a folder called C:\Dsc\Mof. In order to keep authentication simple I'm also assuming that you are logged on to your developer workstation with domain credentials that allow you to perform DSC operations on PRM-DAT-AIO. Running this code will create a PRM-DAT-AIO.mof file in C:\Dsc\Mof which will deploy to PRM-DAT-AIO and create the folder. Magic!
Installing Resource Modules Locally
To do anything much more sophisticated than create a folder we'll need to import resources to our local workstation from the PowerShell Gallery. We'll be working with xWebAdministration and xSQLServer and they can be installed locally as follows:
|
|
Install-Module xWebAdministration -Force -Verbose Install-Module xSQLServer -Force -Verbose |
These same commands will also install the latest version of the resources if a previous version exists. Referencing these resources in our configuration script seems to have changed with the release of DSC 5.0 and versioning information is a requirement. Consequently, these resources are referenced in the configuration as follows:
|
|
Import-DscResource -ModuleName @{ModuleName="xWebAdministration";ModuleVersion="1.10.0.0"} Import-DscResource -ModuleName @{ModuleName="xSQLServer";ModuleVersion="1.5.0.0"} |
Obviously change the above code to reference the version of the module that you actually install. The resources are continually being updated with new versions and this requires a strategy to upgrade on a periodic basis.
Making Resource Modules Available Remotely
Whilst the additions in the previous section allows us to create advanced configurations on our developer workstation these configurations are not going to run against target nodes since as things stand the target nodes don't know anything about custom resources (as opposed to resources such as PSDesiredStateConfiguration which ship with the Windows Management Framework). We can fix this by telling the Local Configuration Manager (LCM) of target nodes where to get the custom resources from. The procedure (which I've adapted from Nana Lakshmanan's blog post) is as follows:
- Choose a server in the domain to host a fileshare. I'm using my domain controller (PRM-CORE-DC) as it's always guaranteed to be available under normal conditions. Create a folder called C:\Dsc\DscResources (Dsc purposefully repeated) and share it as Read/Write for Everyone as \\PRM-CORE-DC\DscResources.
- Custom resources need to be zipped in a format required by DSC the pull protocol. The PowerShell to do this for version 1.10 of xWebAdministration and 1.5 of xSQLServer (using a local C:\Dsc\Resources folder) is as follows:
|
|
Find-Module xWebAdministration | Save-Module -Path C:\Dsc\Resources -Verbose -Force Compress-Archive -Path C:\Dsc\Resources\xWebAdministration\1.10.0.0\* -DestinationPath \\prm-core-dc\DscResources\xWebAdministration_1.10.0.0.zip -Verbose -Force New-DscChecksum -Path \\prm-core-dc\DscResources\xWebAdministration_1.10.0.0.zip -OutPath \\prm-core-dc\DscResources -Verbose -Force Find-Module xSQLServer | Save-Module -Path C:\Dsc\Resources -Verbose -Force Compress-Archive -Path C:\Dsc\Resources\xSQLServer\1.5.0.0\* -DestinationPath \\prm-core-dc\DscResources\xSQLServer_1.5.0.0.zip -Verbose -Force New-DscChecksum -Path \\prm-core-dc\DscResources\xSQLServer_1.5.0.0.zip -OutPath \\prm-core-dc\DscResources -Verbose -Force |
Of course depending on the frequency of your having to do this to cope with updates and the number of resources you end up working with you probably want to re-write all this up in to some sort of reusable package.
- With the packages now in the right format in the fileshare we need to tell the LCM of target nodes where to look. We do this by creating a new configuration decorated with the [DscLocalConfigurationManager()] attribute:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[DscLocalConfigurationManager()] Configuration LocalConfigurationManager { Node $AllNodes.NodeName { Settings { RefreshMode = 'Push' AllowModuleOverwrite = $True # A configuration Id needs to be specified, known bug ConfigurationID = '3a15d863-bd25-432c-9e45-9199afecde91' ConfigurationMode = 'ApplyAndAutoCorrect' RebootNodeIfNeeded = $True } ResourceRepositoryShare FileShare { SourcePath = '\\prm-core-dc\DscResources\' } } } LocalConfigurationManager -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose |
The Settings block is used to set various properties of the LCM which are required in order for configurations we'll be writing to run. The ResourceRepositoryShare block obviously specifies the location of the zipped resource packages.
- The final requirement is to add the line of code (Set-DscLocalConfigurationManager -Path C:\Dsc\Mof -Verbose) to apply the LCM settings.
The revised version of ContosoUniversity.ps1 should now be as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
$configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') } ) } Configuration WebAndDatabase { Import-DscResource –ModuleName PSDesiredStateConfiguration Import-DscResource -ModuleName @{ModuleName="xWebAdministration";ModuleVersion="1.10.0.0"} Import-DscResource -Module @{ModuleName="xSQLServer";ModuleVersion="1.5.0.0"} Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { File WebSiteFolder { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } } } WebAndDatabase -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose [DscLocalConfigurationManager()] Configuration LocalConfigurationManager { Node $AllNodes.NodeName { Settings { RefreshMode = 'Push' AllowModuleOverwrite = $True # A configuration Id needs to be specified, known bug ConfigurationID = '3a15d863-bd25-432c-9e45-9199afecde91' ConfigurationMode = 'ApplyAndAutoCorrect' RebootNodeIfNeeded = $True } ResourceRepositoryShare FileShare { SourcePath = '\\prm-core-dc\DscResources\' } } } LocalConfigurationManager -ConfigurationData $configurationData -OutputPath C:\Dsc\Mof -Verbose Set-DscLocalConfigurationManager -Path C:\Dsc\Mof -Verbose Start-DSCConfiguration -Path C:\Dsc\Mof -Wait -Verbose -Force |
At this stage we now have our complete working framework in place and we can begin writing the configuration blocks that colectively will leave us with a server that is capable of running our Contoso University application.
Writing Configurations for the Web Role
Configuring for the web role requires consideration of the following factors:
- The server features that are required to run your application. For Contoso University that's IIS, .NET Framework 4.5 Core and ASP.NET 4.5.
- The mandatory IIS configurations for your application. For Contoso University that's a web site with a custom physical path.
- The optional IIS configurations for your application. I like things done in a certain way so I want to see an application pool called ContosoUniversity and the Contoso University web site configured to use it.
- Any tidying-up that you want to do to free resources and start thinking like you are configuring NanoServer. For me this means removing the default web site and default application pools.
Although you'll know if your configurations have generated errors how will you know if they've generated the desired result? The following ‘debugging' options can help:
- I know that the home page of Contoso University will load without a connection to a database, so I copied a build of the website to C:\inetpub\ContosoUniversity on PRM-DAT-AIO so I could test the site with a browser. You can download a zip of the build from here although be aware that AV software might mistakenly regard it as malware.
- The IIS management tools can be installed on target nodes whilst you are in configuration mode so you can see graphically what's happening. The following configuration does the trick:
|
|
WindowsFeature IISTools { Ensure = "Present" Name = "Web-Mgmt-Tools" } |
- If you are testing with a local version of Internet Explorer make sure you turn off Compatibility View or your site may render with odd results. From the IE toolbar choose Tools > Compatibility View Settings and uncheck Display intranet sites in Compatibility View.
Whilst you are in configuration mode the following resources will be of assistance:
- The xWebAdministration documentation on GitHub: https://github.com/PowerShell/xWebAdministration.
- The example files that ship with xWebAdministration: C:\Program Files\WindowsPowerShell\Modules\xWebAdministration\n.n.n.n\Examples.
- A Google search for xWebAdministration.
The configuration settings required to meet my requirements stated above are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
Node $AllNodes.Where({$_.Roles -contains 'Web'}).NodeName { # Configure for web server role WindowsFeature DotNet45Core { Ensure = 'Present' Name = 'NET-Framework-45-Core' } WindowsFeature IIS { Ensure = 'Present' Name = 'Web-Server' } WindowsFeature AspNet45 { Ensure = "Present" Name = "Web-Asp-Net45" } # Configure ContosoUniversity File ContosoUniversity { Ensure = "Present" Type = "Directory" DestinationPath = "C:\inetpub\ContosoUniversity" } xWebAppPool ContosoUniversity { Ensure = "Present" Name = "ContosoUniversity" State = "Started" DependsOn = "[WindowsFeature]IIS" } xWebsite ContosoUniversity { Ensure = "Present" Name = "ContosoUniversity" State = "Started" PhysicalPath = "C:\inetpub\ContosoUniversity" BindingInfo = MSFT_xWebBindingInformation { Protocol = 'http' Port = '80' HostName = 'prm-dat-aio' IPAddress = '*' } ApplicationPool = "ContosoUniversity" DependsOn = "[xWebAppPool]ContosoUniversity" } # Configure for development mode only WindowsFeature IISTools { Ensure = "Present" Name = "Web-Mgmt-Tools" } # Clean up the uneeded website and application pools xWebsite Default { Ensure = "Absent" Name = "Default Web Site" } xWebAppPool NETv45 { Ensure = "Absent" Name = ".NET v4.5" } xWebAppPool NETv45Classic { Ensure = "Absent" Name = ".NET v4.5 Classic" } xWebAppPool Default { Ensure = "Absent" Name = "DefaultAppPool" } File wwwroot { Ensure = "Absent" Type = "Directory" DestinationPath = "C:\inetpub\wwwroot" Force = $True } } |
There is one more piece of the jigsaw to finish the configuration and that's amending the application pool to use a domain account that has permissions to talk to SQL Server. That's a more advanced topic so I'm dealing with it later.
Writing Configurations for the Database Role
Configuring for the SQL Server database role is slightly different from the web role since we need to install SQL Server which is a separate application. The installation files need to be made available as follows:
- Choose a server in the domain to host a fileshare. As above I'm using my domain controller. Create a folder called C:\Dsc\DscInstallationMedia and and share it as Read/Write for Everyone as \\PRM-CORE-DC\DscInstallationMedia.
- Download a suitable SQL Server ISO image to the server hosting the fileshare -- I used en_sql_server_2014_enterprise_edition_with_service_pack_1_x64_dvd_6669618.iso from MSDN Subscriber Downloads.
- Mount the ISO and copy the contents of its drive to a folder called SqlServer2014 created under C:\Dsc\DscInstallationMedia.
In contrast to configuring for the web role there are fewer configurations required for the database role. There is a requirement to supply a credential though and for this I'm using the Key Vault technique described in this post. This gives rise to new code within and preceding the configuration hash table as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise $vaultname = 'prmkeyvault' $domainAdminPassword = Get-AzureKeyVaultSecret –VaultName $vaultname –Name DomainAdminPassword $SecurePassword = ConvertTo-SecureString -String $domainAdminPassword.SecretValueText -AsPlainText -Force $domainAdministratorCredential = New-Object System.Management.Automation.PSCredential ("PRM\graham", $SecurePassword) $configurationData = @{ AllNodes = @( @{ NodeName = 'PRM-DAT-AIO' Roles = @('Web', 'Database') AppPoolUserName = 'PRM\CU-DAT' PSDscAllowDomainUser = $true PSDscAllowPlainTextPassword = $true DomainAdministratorCredential = $domainAdministratorCredential } ) } |
For a server such as the one we are configuring where the database is on the same machine as the web server and only the database engine is required there are just two configuration blocks needed to install SQL Server. For more complicated scenarios the following resources will be of assistance:
- The xSQLServer documentation on GitHub: https://github.com/PowerShell/xSQLServer.
- The example files that ship with xSQLServer: C:\Program Files\WindowsPowerShell\Modules\xSQLServer\n.n.n.n\Examples.
- A Google search for xSQLServer.
The configuration settings required for the single server scenario are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Node $AllNodes.Where({$_.Roles -contains 'Database'}).NodeName { WindowsFeature "NETFrameworkCore" { Ensure = "Present" Name = "NET-Framework-Core" } xSqlServerSetup "SQLServerEngine" { DependsOn = "[WindowsFeature]NETFrameworkCore" SourcePath = "\\prm-core-dc\DscInstallationMedia" SourceFolder = "SqlServer2014" SetupCredential = $Node.DomainAdministratorCredential InstanceName = "MSSQLSERVER" Features = "SQLENGINE" } # Configure for development mode only xSqlServerSetup "SQLServerManagementTools" { DependsOn = "[WindowsFeature]NETFrameworkCore" SourcePath = "\\prm-core-dc\DscInstallationMedia" SourceFolder = "SqlServer2014" SetupCredential = $Node.DomainAdministratorCredential InstanceName = "NULL" Features = "SSMS,ADV_SSMS" } } |
In order to assist with ‘debugging' activities I've included the installation of the SQL Server management tools but this can be omitted when the configuration has been tested and deemed fit for purpose. Later in this post we'll manually install the remaining parts of the Contoso University application to prove that the installation worked but for the time being you can run SQL Server Management Studio to see the database engine running in all its glory!
Amending the Application Pool Identity
The Contoso University website is granted access to the database via a domain account that firstly gets configured as the Identity for the website's application pool and then gets configured as a SQL Server login associated with a user which has the appropriate permissions to the database. The SQL Server configuration is taken care of by a permissions script that we'll come to shortly, and the immediate task is concerned with amending the Identity property of the ConsosoUniversity application pool so that it references a domain account.
Initially this looked like it was going to be painful since xWebAdministration doesn't currently have the ability to configure the inner workings of application pools. Whilst investigating the possibilities I had the good fortune to come across a fork of xWebAdministration on the PowerShell.org GitHub site where those guys have created a module which does what we want. I need to introduce a slight element of caution here since the fork doesn't look like it's under active development. On the other hand maybe there are no major issues that need fixing. And if there are and they aren't going to get fixed at least the code is there to be forked. Because this fork isn't in the PowerShell Gallery getting it to work locally is a manual process:
- Download the code to C:\Dsc\Resources and unblock and extract it. Change the folder name from cWebAdministration-master to cWebAdministration and copy to C:\Program Files\WindowsPowerShell\Modules.
- In the configuration block reference the module as Import-DscResource –ModuleName @{ModuleName="cWebAdministration";ModuleVersion="2.0.1″}.
The configuration required to make the resource available to target nodes has an extra manual step:
- In the root of C:\DSC\Resources\cWebAdministration create a folder named 2.0.1 and copy the contents of C:\DSC\Resources\cWebAdministration to this folder.
- The following code can now be used to package the resource and copy it to the fileshare:
|
|
Compress-Archive -Path C:\Dsc\Resources\cWebAdministration\2.0.1\* -DestinationPath \\prm-core-dc\DscResources\cWebAdministration_2.0.1.zip -Verbose -Force New-DscChecksum -Path \\prm-core-dc\DscResources\cWebAdministration_2.0.1.zip -OutPath \\prm-core-dc\DscResources -Verbose -Force |
I tend towards using a different domain account for the Identity properties of the website application pools in the different environments that make up the deployment pipeline. In doing so it protects the pipeline form a complete failure if something happens to that domain account -- it gets locked-out for example. To support this scenario the configuration block to configure the application pool identity needs to support dynamic configuration and takes the following form:
|
|
cAppPool ContosoUniversity { Name = "ContosoUniversity" IdentityType = "SpecificUser" UserName = $Node.AppPoolUserName Password = $Node.AppPoolCredential DependsOn = "[xWebAppPool]ContosoUniversity" } |
The dynamic configuration is supported by Key Vault code to retrieve the password of the domain account used to configure the application pool (not shown) and the following additions to the configuration hash table:
|
|
AppPoolUserName = 'PRM\CU-DAT' AppPoolCredential = $appPoolDomainAccountCredential |
The code does of course rely on the existence of the PRM\CU-DAT domain account (set so the password doesn't expire). This is the last piece of configuration, and you can view the final result on GitHub here.
The Moment of Truth
After all that configuration, is it enough to make the Contoso University application work? To find out:
- If you haven't already, download, unblock and unzip the ContosoUniversityConfigAsCode package from here, although as mentioned previously be aware that AV software might mistakenly regard it as malware.
- The contents of the Website folder should be copied (if not already) to C:\inetpub\ContosoUniversity on the target node.
- Edit the SchoolContext connection string in Web.config if required -- the download has the server set to localhost and the database to ContosoUniversity.
- On the target node run SQL Server Management Studio and install the database as follows:
- In Object Explorer right-click the Databases node and choose Deploy Data-tier Application.
- Navigate through the wizard, and at Select Package choose ContosoUniversity.Database.dacpac from the database folder of the ContosoUniversityConfigAsCode download.
- Move to the next page of the wizard (Update Configuration) and change the Name to ContosoUniversity.
- Navigate past the Summary page and the DACPAC will be deployed:

- Still in SSMS, apply the permissions script as follows:
- Open Create login and database user.sql from the Database\Scripts folder in the ContosoUniversityConfigAsCode download.
- If the pre-configured login/user (PRM\CU-DAT) is different from the one you are using update accordingly, then execute the script.
You can now navigate to http://prm-dat-aio (or whatever your server is called) and if all is well make a mental note to pour a well-deserved beverage of your choosing.
Looking Forward
Although getting this far is certainly an important milestone it's by no means the end of the journey for the configuration as code story. Our configuration code now needs to be integrated in to the Contoso University Visual Studio solution so that it can be built as an artefact alongside the website and database artefacts. We then need to be able to deploy the configuration before deploying the application -- all automated through the new release management tooling that has just shipped with TFS 2015 Update 2 or through VSTS if you are using that. Until next time...
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Join a VM to a Domain with Azure Resource Manager Templates
In the previous post in my blog post series on Continuous Delivery with TFS / VSTS we learned how to provision a Windows Server virtual machine using Azure Resource Manager templates. The next major step in this quest to automate the creation and configuration of the infrastructure to which we'll deploy our application is to configure server internals, starting with joining a VM to the domain. My initial thinking was that this would need to be some kind of PowerShell command, and whilst this is an option I was very pleased to find that there is an ARM template resource to do this. The resource in question goes by the name of JsonADDomainExtension; it's a VM extension and you can read about it (and the PowerShell commands to do the same thing) in this blog post.
I have to confess that I struggled to get the extension to work at first. I spent a whole afternoon fiddling with the settings and getting nowhere, and spent quite a bit of time reading forum posts from others who were having similar difficulties (mostly with the PowerShell commands though). I gave up in frustration, only to come back to it a few days later to try again to find it was all working! I describe the steps I took below -- please be aware that it's very much a direct continuation of this post so please do check that out first if you haven't done so already.
Adding the JsonADDomainExtension to the JSON Template
Getting starting with the extension is very easy, as it's just a case of dropping the JSON in to the resources part of the template. The code I initially used to make the extension work was as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "apiVersion": "2015-06-15", "type": "Microsoft.Compute/virtualMachines/extensions", "name": "[concat(variables('nodeNameToLower'),'/joindomain')]", "location": "[resourceGroup().location]", "dependsOn": [ "[concat('Microsoft.Compute/virtualMachines/', variables('nodeNameToUpper'))]" ], "tags": { "displayName": "JoinDomain" }, "properties": { "publisher": "Microsoft.Compute", "type": "JsonADDomainExtension", "typeHandlerVersion": "1.0", "settings": { "Name": "prm.local", "OUPath": "", "User": "prm\\graham", "Restart": "true", "Options": "3" }, "protectedsettings": { "Password": "MySuperSecureDomainAdminPassword" } } } |
I added this code to the WindowsServer2012R2Datacenter.json file which has variables defined for use where the VM name is required. Note that OUPath can be an empty string, the requirement for the escaped backslash for the (domain) User and the use of the magic number 3 in Options (just go with it or see here for the details).
Whilst this (eventually) worked fine for me the big issue was how to hide the password for the account that will join the VM to the domain. I hard coded it in to the template to get the extension working but even when refactored as a parameter the password is still in plain view -- now just in the PowerShell calling script.
Say Hello to Azure Key Vault
As luck would have it around the time I was initially getting JsonADDomainExtension to work I watched Cloud Cover Episode 200: Azure Resource Manager Tooling with Brian Moore where Brian mentioned the forthcoming ability to use Azure Key Vault to supply secret values such as passwords to ARM templates. Following a very helpful email exchange Brian pointed me towards this page which is a partial answer to the solution I wanted to get working.
At the time of writing there was no portal interface for configuring Azure Key Vault so it's over to PowerShell (no bad thing) to create a new vault:
|
|
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise New-AzureRmKeyVault -VaultName 'prmkeyvault' -ResourceGroupName PRM-COMMON -Location 'West Europe' |
In the code above this creates a vault named prmkeyvault. Next we need to add our password as a secret:
|
|
$secretValue = ConvertTo-SecureString 'MySuperSecureDomainAdminPassword' -AsPlainText -Force Set-AzureKeyVaultSecret -VaultName 'prmkeyvault' -Name 'DomainAdminPassword' -SecretValue $secretValue |
This creates a new secret called DomainAdminPassword. Of course, the objects that have just been created can be examined with Azure Resource Explorer:

Use the Secret in the JSON Template
The Microsoft guidance for passing secrets to templates is based on the use of an ARM parameters file. This wasn't quite what I wanted as I'm using a PowerShell script to supply my parameters. The way to access secrets using PowerShell is along the following lines:
|
|
# Assumes authentication has already been made $domainAdminPassword = Get-AzureKeyVaultSecret –VaultName prmkeyvaulttest –Name DomainAdminAdminPassword # Use this syntax to return the secret $domainAdminPassword.SecretValueText |
You can see how I integrated the code above in to my PowerShell script by examining Create PRM-DAT.ps1 in the code release that accompanies this post on my Infrastructure repository on GitHub. It's not quite the full solution at the moment though because despite having a mechanism in place for automatically authenticating to Azure PowerShell the use of Azure Key Vault cmdlets in the script causes the authentication dialog to pop-up. I'm still working on how to stop that -- if you know please leave a message in the comments!
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Infrastructure as Code with Azure Resource Manager Templates
So far in this blog post series on Continuous Delivery with TFS / VSTS we have gradually worked our way to the position of having a build of our application which is almost ready to be deployed to target servers (or nodes if you prefer) in order to conduct further testing before finally making its way to production. This brings us to the question of how these nodes should be provisioned and configured. In my previous series on continuous delivery deployment was to nodes that had been created and configured manually. However with the wealth of automation tools available to us we can -- and should -- improve on that. This post explains how to achieve the first of those -- provisioning a Windows Server virtual machine using Azure Resource Manager templates. A future post will deal with the configuration side of things using PowerShell DSC.
Before going further I should point out that this post is a bit different from my other posts in the sense that it is very specific to Azure. If you are attempting to implement continuous delivery in an on premises situation chances are that the specifics of what I cover here are not directly usable. Consequently, I'm writing this post in the spirit of getting you to think about this topic with a view to investigating what's possible for your situation. Additionally, if you are not in the continuous delivery space and have stumbled across this post through serendipity I do hope you will be able to follow along with my workflow for creating templates. Once you get past the Big Picture section it's reasonably generic and you can find the code that accompanies this post at my GitHub repository here.
The Infrastructure Big Picture
In order to understand where I am going with this post it's probably helpful to understand the big picture as it relates to this blog series on continuous delivery. Our final continuous delivery pipeline is going to consist of three environments:
- DAT -- development automated test where automated UI testing takes place. This will be an ‘all in one' VM hosting both SQL Server and IIS. Why have an all-in-one VM? It's because the purpose of this environment is to run automated tests, and if those tests fail we want a high degree of certainty that it was because of code and not any other factors such as network problems or a database timeout. To achieve that state of certainty we need to eliminate as many influencing variables as possible, and the simplest way of achieving that is to have everything running on the same VM. It breaks the rule about early environments reflecting production but if you are in an on premises situation and your VMs are on hand-me-down infrastructure and your network is busy at night (when your tests are likely running) backing up VMs and goodness knows what else then you might come to appreciate the need for an all-in-one VM for automated testing.
- DQA -- development quality assurance where high-value manual testing takes place. This really does need to reflect production so it will consist of a database VM and a web server VM.
- PRD -- production for the live code. It will consist of a database VM and a web server VM.
These environments map out to the following infrastructure I'll be creating in Azure:
- PRM-DAT -- resource group to hold everything for the DAT environment
- PRM-DAT-AIO -- all in one VM for the DAT environment
- PRM-DQA -- resource group to hold everything for the DQA environment
- PRM-DQA-SQL -- database VM for the DQA environment
- PRM-DQA-IIS -- web server VM for the DQA environment
- PRM-PRD -- resource group to hold everything for the DQA environment
- PRM-PRD-SQL -- database VM for the PRD environment
- PRM-PRD-IIS -- web server VM for the PRD environment
The advantage of using resource groups as containers is that an environment can be torn down very easily. This makes more sense when you realise that it's not just the VM that needs tearing down but also storage accounts, network security groups, network interfaces and public IP addresses.
Overview of the ARM Template Development Workflow
We're going to be creating our infrastructure using ARM templates which is a declarative approach, ie we declare what we want and some other system ‘makes it so'. This is in contrast to an imperative approach where we specify exactly what should happen and in what order. (We can use an imperative approach with ARM using PowerShell but we don't get any parallelisation benefits.) If you need to get up to speed with ARM templates I have a Getting Started blog post with a collection useful useful links here. The problem -- for me at least -- is that although Microsoft provide example templates for creating a Windows Server VM (for instance) they are heavily parametrised and designed to work as standalone VMs, and it's not immediately obvious how they can fit in to an existing network. There's also the issue that at first glance all that JSON can look quite intimidating! Fear not though, as I have figured out what I hope is a great workflow for creating ARM templates which is both instructive and productive. It brings together a number of tools and technologies and I make the assumption that you are familiar with these. If not I've blogged about most of them before. A summary of the workflow steps with prerequisites and assumptions is as follows:
- Create a Model VM in Azure Portal. The ARM templates that Microsoft provide tend to result in infrastructure that have different internal names compared with the same infrastructure created through the Azure Portal. I like how the portal names things and in order to help replicate that naming convention for VMs I find it useful to create a model VM in the portal whose components I can examine via the Azure Resource Explorer.
- Create a Visual Studio Solution. Probably the easiest way to work with ARM templates is in Visual Studio. You'll need the Azure SDK installed to see the Azure Resource Group project template -- see here for more details. We'll also be using Visual Studio to deploy the templates using PowerShell and for that you'll need the PowerShell Tools for Visual Studio extension. If you are new to this I have a Getting Started blog post here. We'll be using Git in either TFS or VSTS for version control but if you are following this series we've already covered that.
- Perform an Initial Deployment. There's nothing worse than spending hours coding only to find that what you're hoping to do doesn't work and that the problem is hard to trace. The answer of course is to deploy early and that's the purpose of this step.
- Build the Deployment Template Resource by Resource Using Hard-coded Values. The Microsoft templates really go to town when it comes to implementing variables and parameters. That level of detail isn't required here but it's hard to see just how much is required until the template is complete. My workflow involves using hard-coded values initially so the focus can remain on getting the template working and then refactoring later.
- Refactor the Template with Parameters, Variables and Functions. For me refactoring to remove the hard-coded values is one of most fun and rewarding parts of the process. There's a wealth of programming functionality available in ARM templates -- see here for all the details.
- Use the Template to Create Multiple VMs. We've proved the template can create a single VM -- what about multiple VMs? This section explores the options.
That's enough overview -- time to get stuck in!
Create a Model VM in Azure Portal
As above, the first VM we'll create using an ARM template is going to be called PRM-DAT-AIO in a resource group called PRM-DAT. In order to help build the template we'll create a model VM called PRM-DAT-AAA in a resource group called PRM-DAT via the Azure Portal. The procedure is as follows:
- Create a resource group called PRM-DAT in your preferred location -- in my case West Europe.
- Create a standard (Standard-LRS) storage account in the new resource group -- I named mine prmdataaastorageaccount. Don't enable diagnostics.
- Create a Windows Server 2012 R2 Datacenter VM (size right now doesn't matter much -- I chose Standard DS1 to keep costs down) called PRM-DAT-AAA based on the PRM-DAT resource group, the prmdataaastorageaccount storage account and the prmvirtualnetwork that was created at the beginning of this blog series as the common virtual network for all VMs. Don't enable monitoring.
- In Public IP addresses locate PRM-DAT-AAA and under configuration set the DNS name label to prm-dat-aaa.
- In Network security groups locate PRM-DAT-AAA and add the following tag: displayName : NetworkSecurityGroup.
- In Network interfaces locate PRM-DAT-AAAnnn (where nnn represents any number) and add the following tag: displayName : NetworkInterface.
- In Public IP addresses locate PRM-DAT-AAA and add the following tag: displayName : PublicIPAddress.
- In Storage accounts locate prmdataaastorageaccount and add the following tag: displayName : StorageAccount.
- In Virtual machines locate PRM-DAT-AAA and add the following tag: displayName : VirtualMachine.
You can now explore all the different parts of this VM in the Azure Resource Explorer. For example, the public IP address should look similar to:

Create a Visual Studio Solution
We'll be building and running our ARM template in Visual Studio. You may want to refer to previous posts (here and here) as a reminder for some of the configuration steps which are as follows:
- In the Web Portal navigate to your team project and add a new Git repository called Infrastructure.
- In Visual Studio clone the new repository to a folder called Infrastructure at your preferred location on disk.
- Create a new Visual Studio Solution (not project!) called Infrastructure one level higher then the Infrastructure folder. This effectively stops Visual Studio from creating an unwanted folder.
- Add .gitignore and .gitattributes files and perform a commit.
- Add a new Visual Studio Project to the solution of type Azure Resource Group called DeploymentTemplates. When asked to select a template choose anything.
- Delete the Scripts, Templates and Tools folders from the project.
- Add a new project to the solution of type PowerShell Script Project called DeploymentScripts.
- Delete Script.ps1 from the project.
- In the DeploymentTemplates project add a new Azure Resource Manager Deployment Project item called WindowsServer2012R2Datacenter.json (spaces not allowed).
- In the DeploymentScripts project add a new PowerShell Script item for the PowerShell that will create the PRM-DAT resource group with a PRM-DAT-AIO server -- I called my file Create PRM-DAT.ps1.
- Perform a commit and sync to get everything safely under version control.
With all that configuration you should have a Visual Studio solution looking something like this:

Perform an Initial Deployment
It's now time to write just enough code in Create PRM-DAT.ps1 to prove that we can initiate a deployment from PowerShell. First up is the code to authenticate to Azure PowerShell. I have the authentication code which was the output of this post wrapped in a function called Set-AzureRmAuthenticationForMsdnEnterprise which in turn is contained in a PowerShell module file called Authentication.psm1. This file in turn is deployed to C:\Users\Graham\Documents\WindowsPowerShell\Modules\Authentication which then allows me to call Set-AzureRmAuthenticationForMsdnEnterprise from anywhere on my development machine. (Although this function could clearly be made more generic with the use of some parameters I've consciously chosen not to so I can check my code in to GitHub without worrying about exposing any authentication details.) The initial contents of Create PRM-DAT.ps1 should end up looking as follows:
|
|
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise # Make sure we can get the root of the solution wherever it's installed to $solutionRoot = Split-Path -Path $MyInvocation.MyCommand.Definition -Parent # Always need the resource group to be present New-AzureRmResourceGroup -Name PRM-DAT -Location westeurope -Force # Deploy the contents of the template New-AzureRmResourceGroupDeployment -ResourceGroupName PRM-DAT ` -TemplateFile "$solutionRoot\..\DeploymentTemplates\WindowsServer2012R2Datacenter.json" ` -Force -Verbose |
Running this code in Visual Studio should result in a successful outcome, although admittedly not much has happened because the resource group already existed and the deployment template is empty. Nonetheless, it's progress!
Build the Deployment Template Resource by Resource Using Hard-coded Values
The first resource we'll code is a storage account. In the DeploymentTemplates project open WindowsServer2012R2Datacenter.json which as things stand just contains some boilerplate JSON for the different sections of the template that we'll be completing. What you should notice is the JSON Outline window is now available to assist with editing the template. Right-click resources and choose Add New Resource:

In the Add Resource window find Storage Account and add it with the name (actually the display name) of StorageAccount:

This results in boilerplate JSON being added to the template along with a variable for actual storage account name and a parameter for account type. We'll use a variable later but for now delete the variable and parameter that was added -- you can either use the JSON Outline window or manually edit the template.
We now need to edit the properties of the resource with actual values that can create (or update) the resource. In order to understand what to add we can use the Azure Resource Explorer to navigate down to the storageAccounts node of the MSDN subscription where we created prmdataaastorageaccount:

In the right-hand pane of the explorer we can see the JSON that represents this concrete resource, and although the properties names don't always match exactly it should be fairly easy to see how the ‘live' values can be used as a guide to populating the ones in the deployment template:

So, back to the deployment template the following unassigned properties can be assigned the following values:
- "name": "prmdataiostorageaccount"
- "location": "West Europe"
- "accountType": "Standard_LRS"
The resulting JSON should be similar to:
|
|
{ "name": "prmdataiostorageaccount", "type": "Microsoft.Storage/storageAccounts", "location": "West Europe", "apiVersion": "2015-06-15", "dependsOn": [ ], "tags": { "displayName": "StorageAccount" }, "properties": { "accountType": "Standard_LRS" } } |
Save the template and switch to Create PRM-DAT.ps1 to run the deployment script which should create the storage account. You can verify this either via the portal or the explorer.
The next resource we'll create is a NetworkSecurityGroup, which has an extra twist in that at the time of writing adding it to the template isn't supported by the JSON Outline window. There's a couple of ways to go here -- either type the JSON by hand or use the Create function in the Azure Resource Explorer to generate some boilerplate JSON. This latter technique actually generates more JSON than is needed so in this case is something of a hindrance. I just typed the JSON directly and made use of the IntelliSense options in conjunction with the PRM-DAT-AAA network security group values via the Azure Resource Explorer. The JSON that needs adding is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ "name": "PRM-DAT-AIO", "type": "Microsoft.Network/networkSecurityGroups", "location": "West Europe", "apiVersion": "2015-06-15", "tags": { "displayName": "NetworkSecurityGroup" }, "properties": { "securityRules": [ { "name": "default-allow-rdp", "properties": { "protocol": "Tcp", "sourcePortRange": "*", "destinationPortRange": "3389", "sourceAddressPrefix": "*", "destinationAddressPrefix": "*", "access": "Allow", "priority": 1000, "direction": "Inbound" } } ] } } |
Note that you'll need to separate this resource from the storage account resource with a comma to ensure the syntax is valid. Save the template, run the deployment and refresh the Azure Resource Explorer. You can now compare the new PRM-DAT-AIO and PRM-DAT-AAA network security groups in the explorer to validate the JSON that creates PRM-DAT-AIO. Note that by zooming out in your browser you can toggle between the two resources and see that it is pretty much just the etag values that are different.
The next resource to add is a public IP address. This can be added from the JSON Outline window using PublicIPAddress as the name but it also wants to add a reference to itself to a network interface which in turn wants to reference a virtual network. We are going to use an existing virtual network but we do need a network interface, so give the new network interface a name of NetworkInterface and the new virtual network can be any temporary name. As soon as the new JSON components have been added delete the virtual network and all of the variables and parameters that were added. All this makes sense when you do it -- trust me!
Once edited with the appropriate values the JSON for the public IP address should be as follows:
|
|
{ "name": "PRM-DAT-AIO", "type": "Microsoft.Network/publicIPAddresses", "location": "West Europe", "apiVersion": "2015-06-15", "tags": { "displayName": "PublicIPAddress" }, "properties": { "publicIPAllocationMethod": "Dynamic", "dnsSettings": { "domainNameLabel": "prm-dat-aio" } } } |
The edited JSON for the network interface should look similar to the code that follows, but note I've replaced my MSDN subscription GUID with an ellipsis.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
{ "name": "prm-dat-aio123", "type": "Microsoft.Network/networkInterfaces", "location": "West Europe", "apiVersion": "2015-06-15", "dependsOn": [ "[concat('Microsoft.Network/publicIPAddresses/', 'PRM-DAT-AIO')]", "[concat('Microsoft.Network/networkSecurityGroups/', 'PRM-DAT-AIO')]" ], "tags": { "displayName": "NetworkInterface" }, "properties": { "ipConfigurations": [ { "name": "ipconfig1", "properties": { "privateIPAllocationMethod": "Dynamic", "subnet": { "id": "/subscriptions/.../resourceGroups/PRM-COMMON/providers/Microsoft.Network/virtualNetworks/prmvirtualnetwork/subnets/default" }, "publicIPAddress": { "id": "/subscriptions/.../resourceGroups/PRM-DAT/providers/Microsoft.Network/publicIPAddresses/PRM-DAT-AIO" } } } ], "networkSecurityGroup": { "id": "/subscriptions/.../resourceGroups/PRM-DAT/providers/Microsoft.Network/networkSecurityGroups/PRM-DAT-AIO" } } } |
It's worth remembering at this stage that we're hard-coding references to other resources. We'll fix that up later on, but for the moment note that the network interface needs to know what virtual network subnet it's on (created in an earlier post), and which public IP address and network security group it's using. Also note the dependsOn section which ensures that these resources exist before the network interface is created. At this point you should be able to run the deployment and confirm that the new resources get created.
Finally we can add a Windows virtual machine resource. This is supported from the JSON Outline window, however this resource wants to reference a storage account and virtual network. The storage account exists and that should be selected, but once again we'll need to use a temporary name for the virtual network and delete it and the variables and parameters. Name the virtual machine resource VirtualMachine. Edit the JSON with appropriate hard-coded values which should end up looking as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
{ "name": "PRM-DAT-AIO", "type": "Microsoft.Compute/virtualMachines", "location": "West Europe", "apiVersion": "2015-06-15", "dependsOn": [ "[concat('Microsoft.Storage/storageAccounts/', 'prmdataiostorageaccount')]", "[concat('Microsoft.Network/networkInterfaces/', 'prm-dat-aio123')]" ], "tags": { "displayName": "VirtualMachine" }, "properties": { "hardwareProfile": { "vmSize": "Standard_DS1" }, "osProfile": { "computerName": "PRM-DAT-AIO", "adminUsername": "prmadmin", "adminPassword": "Mystrongpasswordhere9" }, "storageProfile": { "imageReference": { "publisher": "MicrosoftWindowsServer", "offer": "WindowsServer", "sku": "2012-R2-Datacenter", "version": "latest" }, "osDisk": { "name": "PRM-DAT-AIO", "vhd": { "uri": "https://prmdataiostorageaccount.blob.core.windows.net/vhds/PRM-DAT-AIO.vhd" }, "caching": "ReadWrite", "createOption": "FromImage" } }, "networkProfile": { "networkInterfaces": [ { "id": "/subscriptions/.../resourceGroups/PRM-DAT/providers/Microsoft.Network/networkInterfaces/prm-dat-aio123" } ] } } } |
Running the deployment now should result in a complete working VM which you can remote in to.
The final step before going any further is to tear-down the PRM-DAT resource group and check that a fully-working PRM-DAT-AIO VM is created. I added a Destroy PRM-DAT.ps1 file to my DeploymentScripts project with the following code:
|
|
# Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise # Deletes all resources in the resource group!! Remove-AzureRmResourceGroup -Name PRM-DAT -Force |
Refactor the Template with Parameters, Variables and Functions
It's now time to make the template reusable by refactoring all the hard-coded values. Each situation is likely to vary but in this case my specific requirements are:
- The template will always create a Windows Server 2012 R2 Datacenter VM, but obviously the name of the VM needs to be specified.
- I want to restrict my VMs to small sizes to keep costs down.
- I'm happy for the VM username to always be the same so this can be hard-coded in the template, whilst I want to pass the password in as a parameter.
- I'm adding my VMs to an existing virtual network in a different resource group and I'm making a concious decision to hard-code these details in.
- I want the names of all the different resources to be generated using the VM name as the base.
These requirements gave rise to the following parameters, variables and a resource function:
- nodeName parameter -- this is used via variable conversions throughout the template to provide consistent naming of objects. My node names tend to be of the format used in this post and that's the only format I've tested. Beware if your node names are different as there are naming rules in force.
- nodeNameToUpper variable -- used where I want to ensure upper case for my own naming convention preferences.
- nodeNameToLower variable -- used where lower case is a requirement of ARM eg where nodeName forms part of a DNS entry.
- vmSize parameter -- restricts the template to creating VMs that are not going to burn Azure credits too quickly and which use standard storage.
- storageAccountName variable -- creates a name for the storage account that is based on a lower case nodeName.
- networkInterfaceName variable -- creates a name for the network interface based on a lower case nodeName with a number suffix.
- virtualNetworkSubnetName variable -- used to create the virtual network subnet which exists in a different resource group and requires a bit of construction work.
- vmAdminUsername variable -- creates a username for the VM based on the nodeName. You'll probably want to change this.
- vmAdminPassword parameter -- the password for the VM passed-in as a secure string.
- resourceGroup().location resource function -- neat way to avoid hard-coding the location in to the template.
Of course, these refactorings shouldn't affect the functioning of the template, and tearing down the PRM-DAT resource group and recreating it should result in the same resources being created.
What about Environments where Multiple VMs are Required?
The work so far has been aimed at creating just one VM, but what if two or more VMs are needed? It's a very good question and there are at least two answers. The first involves using the template as-is and calling New-AzureRmResourceGroupDeployment in a PowerShell Foreach loop. I've illustrated this technique in Create PRM-DQA.ps1 in the DeploymentScripts project. Whilst this works very nicely the VMs are created in series rather than in parallel and, well, who wants to wait? My first thought at creating VMs in parallel was to extend the Foreach loop idea with the -parallel switch in a PowerShell workflow. The code which I was hoping would work looks something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
workflow Create-WindowsServer2012R2Datacenter { param ([string[]] $vms, [string] $resourceGroupName, [string] $solutionRoot) Foreach -parallel($vm in $vms) { # Authentication details are abstracted away in a PS module Set-AzureRmAuthenticationForMsdnEnterprise New-AzureRmResourceGroupDeployment -ResourceGroupName $resourceGroupName ` -TemplateFile "$solutionRoot\..\DeploymentTemplates\WindowsServer2012R2Datacenter.json" ` -Force ` -Verbose ` -Mode Incremental ` -TemplateParameterObject @{ nodeName = $vm; vmSize = 'Standard_DS1'; vmAdminPassword = 'MySuperSecurePassword' } } } $resourceGroupName = 'PRM-PRD' New-AzureRmResourceGroup -Name $resourceGroupName -Location westeurope -Force $virtualmachines = "$resourceGroupName-SQL", "$resourceGroupName-IIS" Create-WindowsServer2012R2Datacenter -vms $virtualmachines -resourceGroupName $resourceGroupName -solutionRoot $PSScriptRoot |
Unfortunately it seems like this idea is a dud -- see here for the details. Instead the technique appears to be to use the copy, copyindex and length features of ARM templates as documented here. This necessitates a minor re-write of the template to pass in and use an array of node names, however there are complications where I've used variables to construct resource names. At the time of publishing this post I'm working through these details -- keep an eye on my GitHub repository for progress.
Wrap-Up
Before actually wrapping-up I'll make a quick mention of the template's outputs node. A handy use for this is debugging, for example where you are trying to construct a complicated variable and want to check its value. I've left an example in the template to illustrate.
I'll finish this post with a question that I've been pondering as I've been writing this post, which is whether just because we can create and configure VMs at the push of a button does that mean we should create and configure new VMs every time we deploy our application? My thinking at the moment is probably not because of the time it will add but as always it depends. If you want a clean start every time you deploy then you certainly have that option, but my mind is already thinking ahead to the additional amount of time it's going to take to actually configure these VMs with IIS and SQL Server. Never say never though, as who knows what's in store for the future? As Azure (presumably) gets faster and VMs become more lightweight with the arrival of Nano Server perhaps creating and configuring VMs from scratch as part of the deployment pipeline will be so fast that there would be no reason not to. Or maybe we'll all be using containers by then...
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Enhancing a CI Build to Help Bake Quality In
In the previous instalment of this blog post series on Continuous Delivery with TFS / VSTS we created a basic CI build. In this post we enhance the CI build with further configurations that can help bake quality in to the application. Just a reminder that I’m using TFS to create my CI build as it’s the lowest common denominator. If you are using VSTS you can obviously follow along but do note that screenshots might vary slightly.
Set Branch Policies
Although it's only marginally related to build this is probably a good point to set branch policies for the master branch of the ContosoUniversity repository. In the Web Portal for the team project click on the cog icon at the far right of the blue banner bar:

This will open up the Control panel at the team project administration page. Navigate to the Version Control tab and in the Repositories pane navigate down to master. In the right pane select Branch Policies:

The branch policies window contains configuration settings that block poor code from polluting the code base. The big change is that the workflow now changes from being able to commit to the master branch directly to having to use pull requests to make commits. This is a great way of enforcing code reviews and I have more detail on the workflow here. In the screenshot above I've selected all the options, including selecting the ContosoUniveristy.CI build to be run when a pull request is created. This blocks any pull requests that would cause the build to fail. The other options are self explanatory, although enforcing a linked work item can be a nuisance when you are testing. If you are testing on your own make sure you Allow users to approve their own changes otherwise this will cause you a problem.
Testing Times
The Contoso University sample application contains MSTest unit tests and we want these to be run after the build to provide early feedback of any failing tests. This is a achieved by adding a new build step. On the Build tab in the Web Portal navigate to the ContosoUniversity.CI build and place it in edit mode. Click on Add build step and from the Add Tasks window filter on Test and choose Visual Studio Test.
For our simple scenario there are only three settings that need addressing:
- Test Assembly -- we only want unit tests to run and ContosoUniversity contains other tests so changing the default setting to **\*UnitTests*.dll;-:**\obj\** fixes this.
- Platform -- here we use the $(BuildPlatform) variable defined in the build task.
- Configuration -- here we use the $(BuildConfiguration) variable defined in the build task.

With the changes saved queue the build and observe the build report advising that the tests were run and passed:

Code Coverage
In the above screenshot you'll notice that there is no code coverage data available. This can be fixed by going back to the Visual Studio Test task and checking the Code Coverage Enabled box. Queueing a new build now gives us that data:

Of slight concern is that the code coverage reported from the build (2.92%) was marginally higher than that reported by analysing code coverage in Visual Studio (2.89%). Whilst the values are the same for all practical purposes the results suggest that there is something odd going on here that warrants further investigation.
Code Analysis
A further feedback item which is desirable to have in the build report is the results of code analysis. (As a reminder, we configured this in Visual Studio in this post so that the results are available after building locally.) Displaying code analysis results in the build report is straightforward for XAML builds as this is an out-of-the-box setting -- see here. I haven't found this to be quite so easy with the new build system.There's no setting as with XAML builds but that shouldn't be a problem since it's just an MSBuild argument. It feels like the correct argument should be /p:RunCodeAnalysis=Always (as this shouldn't care how code analysis is configured in Visual Studio) however in my testing I couldn't get this to work with any combination of the Visual Studio Build / MSBuild task and release / debug configurations. Next argument I tried was /p:RunCodeAnalysis=True. This worked with either Visual Studio Build or MSBuild task but to get it to work in a release configuration you will need to ensure that code analysis has been enabled for the release configuration in Visual Studio (and the change has been committed!). The biggest issue though was that I never managed to get more than 10 code analysis rules displayed in the build report when there were 85 reported in the build output. Perhaps I'm missing something here -- if you can shed any light on this please let me know!
Don't Ignore the Feedback!
Finally, it may sound obvious but there's little point in configuring the build report to contain feedback on the quality of the build if nobody is looking at the reports and is doing something to remedy problems. However you do it this needs to be part of your team's daily routine!
Cheers -- Graham
Continuous Delivery with TFS / VSTS – Configuring a Basic CI Build with Team Foundation Build 2015
In this instalment of my blog post series on Continuous Delivery with TFS / VSTS we configure a continuous integration (CI) build for our Contoso University sample application using Team Foundation Build 2015. Although the focus of this post is on explaining how to configure a build in TFS or VSTS it is worth a few words on the bigger picture as far as builds are concerned.
One important aspect to grasp is that for a given application you are likely to need several different builds for different parts of the delivery pipeline. The focus in this post is a CI build where the main aim is the early detection of problems and additional configurations that help bake quality in. The output from the build is really just information, ie feedback. We're not going to do anything with the build itself so there is no need to capture the compiled output of the build. This is just as well since the build might run very frequently and consequently needs to have a low drain on build server resources.
In addition to a CI build a continuous delivery pipeline is likely to need other types of build. These might include one to support technical debt management (we'll be looking at using SonarQube for this in a later post but look here if you want a sneak preview of what's in store) and one or more that capture the compiled output of the build and kick-off a release to the pipeline.
Before we get going it's worth remembering that as far as new features are concerned VSTS is always a few months ahead of TFS. Consequently I'm using TFS to create my CI build as it's the lowest common denominator. If you are using VSTS you can obviously follow along but do note that screenshots might vary slightly. It's also worth pointing out that starting with TFS 2015 there is a brand new build system that is completely different from the (still supported) XAML system that has been around for the past few years. The new system is recommended for any new implementations and that's what we're using here. If you want to learn more I have a Getting Started blog post here.
Building Blocks
The new build system (which Microsoft abbreviates as TFBuild) is configured from the Web Portal rather than Visual Studio, so head over there and navigate to your team project and then to the Build tab. Click on the green plus icon in the left-hand pane which brings up the Definition Templates window. There's a couple of ways to go from here but for demonstration purposes select the Empty option:

This creates a new empty definition, which does involve a bit of extra work but is worth it the first time to help understand what's going on. Before proceeding lick on Save and provide a name (I chose ContosoUniversity.CI) and optionally a comment for the version control history. Next click the green plus icon next to Add build step to display the Add Tasks window. Take a minute to marvel at the array of possibilities before choosing Visual Studio Build. This gives us a skeleton build which needs configuring by working through the different tabs:

There are many items that can be configured across the different tabs but I'm restricting my explanation to the ones that are not pre-populated and which required. You can find out more about the Visual Studio Build task here.
On the Build tab:
- Platform relates to whether the build should be x86, x64 or any cpu. Whilst you could specify a value here the recommendation is to use a build variable (defined under Variables -- see below) as Platform is a setting used in other build tasks. An additional advantage is that the value of the variable can be changed when the build is queued. As per the documentation I specified $(BuildPlatform) as the variable.
- Configuration is the Visual Studio Solution Configuration you want to build -- typically debug or release. This is another setting used in other build tasks and which warrants a variable and I again followed the documentation and used $(BuildConfiguration).
- Clean forces the code to be refreshed on every build and is recommended to avoid possible between-build discrepancies.

On the Repository tab:
- Clean here appears to be the same as Clean on the Build tab. Not sure why there is duplication or why it is a check box on the Build tab and a dropdown on this tab but set it to true.

On the Variables tab:
- Add a variable named BuildPlatform, specify a value of any cpu and check Allow at Queue Time.
- Add a variable named BuildConfiguration, specify a value of release and check Allow at Queue Time.
On the Triggers tab:
- Continuous Integration should be checked.

That should be enough configuration to get the build to go green. Perform a save and click on Queue build (next to the save button). You will see the output of the build process which should result in the build succeeding:

It's All in the Name
At the moment our build doesn't have a name, so to fix that first head over to the Variables tab and add MajorVersion and MinorVersion variables and give them values of 1 and 0 respectively. Also check the Allow at Queue Time boxes. Now on the General tab enter $(BuildDefinitionName)_$(MajorVersion).$(MinorVersion).$(Year:yyyy)$(DayOfYear)$(Rev:.r) in the Build number format text box. Save the definition and queue a new build. The name should be something like ContosoUniversity.CI_1.0.2016019.2. One nice touch is that the revision number is reset on a daily basis providing an easy way keep track of the builds on a given day.
At this point we have got the basics of a CI build configured and working nicely. In the next post we look at further configurations focussed on helping to bake quality in to the application.
Cheers -- Graham